|
MOAB: Mesh Oriented datABase
(version 5.4.1)
|
|
MOAB: Mesh Oriented datABase
(version 5.4.1)
|
#include <ParallelHelper.hpp>
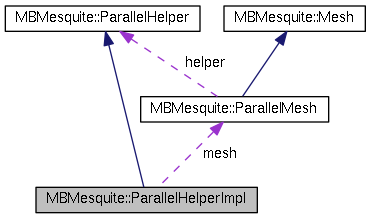
 Inheritance diagram for MBMesquite::ParallelHelperImpl: Collaboration diagram for MBMesquite::ParallelHelperImpl:
Inheritance diagram for MBMesquite::ParallelHelperImpl: Collaboration diagram for MBMesquite::ParallelHelperImpl:Definition at line 69 of file ParallelHelper.hpp.
| TrulyNonBlocking | |
| TrulyNonBlockingAvoidAllReduce | |
| NonBlocking | |
| NonBlockingAvoidAllReduce | |
| Blocking | |
| BlockingAvoidAllReduce |
Definition at line 72 of file ParallelHelper.hpp.
Definition at line 303 of file ParallelHelper.cpp.
References communication_model, communicator, exportProc, exportVtxGIDs, exportVtxLIDs, generate_random_numbers, in_independent_set, mesh, MPI_COMM_WORLD, neighbourProc, neighbourProcRecv, neighbourProcRecvRemain, neighbourProcSend, neighbourProcSendRemain, nprocs, part_gid, part_proc_owner, part_rand_number, part_smoothed_flag, part_vertices, rank, set_communicator(), TrulyNonBlockingAvoidAllReduce, unghost_vertices, vertices, vid_map, vtx_in_partition_boundary, and vtx_off_proc_list.
{
mesh = 0;
set_communicator( MPI_COMM_WORLD );
communication_model = TrulyNonBlockingAvoidAllReduce;
MPI_Comm_rank( (MPI_Comm)communicator, &rank );
MPI_Comm_size( (MPI_Comm)communicator, &nprocs );
// variable defaults for VertexMover::loop_over_mesh()
generate_random_numbers = 2;
// memory chunks referenced for VertexMover::loop_over_mesh()
vertices.clear();
vtx_in_partition_boundary.clear();
part_vertices.clear();
unghost_vertices.clear();
part_proc_owner.clear();
part_gid.clear();
part_smoothed_flag.clear();
part_rand_number.clear();
exportVtxGIDs.clear();
exportVtxLIDs.clear();
exportProc.clear();
in_independent_set.clear();
vid_map.clear();
neighbourProcSend.clear();
neighbourProcRecv.clear();
neighbourProcSendRemain.clear();
neighbourProcRecvRemain.clear();
vtx_off_proc_list.clear();
neighbourProc.clear();
}
Definition at line 337 of file ParallelHelper.cpp.
{}
| int MBMesquite::ParallelHelperImpl::comm_smoothed_vtx_b | ( | MsqError & | err | ) | [private] |
Definition at line 2286 of file ParallelHelper.cpp.
References ARRPTR, CHECK_MPI_RZERO, communicator, exportProc, exportVtxGIDs, exportVtxLIDs, iteration, mesh, MSQ_ERRZERO, neighbourProc, num_exportVtx, part_smoothed_flag, part_vertices, rank, MBMesquite::Vector3D::set(), VERTEX_BLOCK, VERTEX_HEADER, MBMesquite::vertex_map_find(), MBMesquite::Mesh::vertex_set_coordinates(), MBMesquite::Mesh::vertices_get_coordinates(), vid_map, MBMesquite::Vector3D::y(), z, and MBMesquite::Vector3D::z().
Referenced by communicate_first_independent_set(), and communicate_next_independent_set().
{
int i, j, rval;
// printf("[%d] %d %d blocking\n",rank, iteration, pass);fflush(NULL);
/* how many vertices per processor */
std::vector< int > numVtxPerProc( neighbourProc.size(), 0 );
for( i = 0; i < num_exportVtx; i++ )
{
for( j = 0; j < (long)neighbourProc.size(); j++ )
{
if( exportProc[i] == neighbourProc[j] )
{
/* increment count */
numVtxPerProc[j]++;
/* end loop */
break;
}
/* assert loop did not end without finding the processor */
assert( j != (long)neighbourProc.size() );
}
}
/* place vertices going to the same processor into consecutive memory space */
std::vector< VertexPack > vertex_pack( num_exportVtx + 10 ); /* add 10 to have enough memory */
std::vector< VertexPack* > packed_vertices( neighbourProc.size() );
VertexPack* packing_vertex;
packed_vertices[0] = ARRPTR( vertex_pack );
for( i = 1; i < (long)neighbourProc.size(); i++ )
{
packed_vertices[i] = packed_vertices[i - 1] + numVtxPerProc[i - 1];
}
std::vector< int > numVtxPackedPerProc( neighbourProc.size(), 0 );
for( i = 0; i < num_exportVtx; i++ )
{
for( j = 0; j < (long)neighbourProc.size(); j++ )
{
if( exportProc[i] == neighbourProc[j] )
{
packing_vertex = packed_vertices[j] + numVtxPackedPerProc[j];
numVtxPackedPerProc[j]++;
MBMesquite::MsqVertex coordinates;
mesh->vertices_get_coordinates( &part_vertices[exportVtxLIDs[i]], &coordinates, 1, err );
MSQ_ERRZERO( err );
packing_vertex->x = coordinates[0];
packing_vertex->y = coordinates[1];
packing_vertex->z = coordinates[2];
packing_vertex->glob_id = exportVtxGIDs[i];
}
}
}
// delete [] numVtxPackedPerProc;
/* send each block so the corresponding processor preceeded by the number of vertices */
for( j = 0; j < (long)neighbourProc.size(); j++ )
{
// printf("[%d]i%dp%d Announcing %d vertices to proc
// %d\n",rank,iteration,pass,numVtxPerProc[j],neighbourProc[j]); fflush(NULL);
rval = MPI_Send( &( numVtxPerProc[j] ), 1, MPI_INT, neighbourProc[j], VERTEX_HEADER + iteration,
(MPI_Comm)communicator );
CHECK_MPI_RZERO( rval, err );
// printf("[%d]i%dp%d Sending %d vertices to proc
// %d\n",rank,iteration,pass,numVtxPerProc[j],neighbourProc[j]); fflush(NULL);
/* is there any vertex data to be sent */
if( numVtxPerProc[j] )
{
rval = MPI_Send( packed_vertices[j], 4 * numVtxPerProc[j], MPI_DOUBLE, neighbourProc[j],
VERTEX_BLOCK + iteration, (MPI_Comm)communicator );
CHECK_MPI_RZERO( rval, err );
// printf("[%d]i%dp%d Sent %d vertices to proc
// %d\n",rank,iteration,pass,numVtxPerProc[j],neighbourProc[j]); fflush(NULL);
}
}
int num;
int proc;
// int tag;
int count;
int numVtxImport = 0;
MPI_Status status;
int local_id;
// printf("[%d]i%dp%d Waiting to receive vertices from %d processors ...
// \n",rank,iteration,pass,neighbourProc.size()); fflush(NULL);
/* receiving blocks from other processors */
for( j = 0; j < (long)neighbourProc.size(); j++ )
{
rval = MPI_Recv( &num, /* message buffer */
1, /* one data item */
MPI_INT, /* of type int */
MPI_ANY_SOURCE, /* receive from any sender */
VERTEX_HEADER + iteration, /* receive only VERTEX HEADERs */
(MPI_Comm)communicator, /* default communicator */
&status ); /* info about the received message */
CHECK_MPI_RZERO( rval, err );
proc = status.MPI_SOURCE;
// tag = status.MPI_TAG;
MPI_Get_count( &status, MPI_INT, &count );
// printf("[%d]i%dp%d Receiving %d vertices from proc
// %d/%d/%d\n",rank,iteration,pass,num,proc,tag,count); fflush(NULL);
/* is there any vertex data to be received */
if( num )
{
numVtxImport += num;
/* do we have enough space allocated */
if( num_exportVtx + 10 < num )
{
// if (vertex_pack) free(vertex_pack);
num_exportVtx = num;
vertex_pack.resize( num_exportVtx + 10 );
// vertex_pack = (VertexPack*)malloc(sizeof(VertexPack)*(num_exportVtx+10));
}
rval = MPI_Recv( ARRPTR( vertex_pack ), /* message buffer */
4 * num, /* num data's item with 4 doubles each */
MPI_DOUBLE, /* of type double */
proc, /* receive from this procesor only */
VERTEX_BLOCK + iteration, /* receive only VERTEX BLOCKs */
(MPI_Comm)communicator, /* default communicator */
&status ); /* info about the received message */
CHECK_MPI_RZERO( rval, err );
proc = status.MPI_SOURCE;
// tag = status.MPI_TAG;
MPI_Get_count( &status, MPI_DOUBLE, &count );
if( count != 4 * num )
printf( "[%d]i%d WARNING: expected %d vertices = %d bytes from proc %d but only "
"got %d bytes\n",
rank, iteration, num, num * 4, proc, count );
fflush( NULL );
// printf("[%d]i%d Received %d vertices from proc
// %d/%d/%d\n",rank,iteration,num,proc,tag,count); fflush(NULL);
/* update the received vertices in our boundary mesh */
for( i = 0; i < num; i++ )
{
/* printf("[%d]i%d updating vertex %d with global_id
* %d\n",rank,iteration,i,(int)(vertex_pack[i].glob_id)); fflush(NULL); */
local_id = vertex_map_find( vid_map, (int)( vertex_pack[i].glob_id ), proc );
if( local_id )
{
MBMesquite::Vector3D coordinates;
coordinates.set( vertex_pack[i].x, vertex_pack[i].y, vertex_pack[i].z );
mesh->vertex_set_coordinates( part_vertices[local_id], coordinates, err );
MSQ_ERRZERO( err );
assert( part_smoothed_flag[local_id] == 0 );
part_smoothed_flag[local_id] = 1;
if( 0 )
printf( "[%d]i%d updating vertex with global_id %d to %g %g %g \n", rank, iteration,
(int)( vertex_pack[i].glob_id ), vertex_pack[i].x, vertex_pack[i].y, vertex_pack[i].z );
}
else
{
printf( "[%d]i%d vertex with gid %lu and pid %d not in map\n", rank, iteration,
vertex_pack[i].glob_id, proc );
}
}
}
}
// if (vertex_pack) free(vertex_pack);
return numVtxImport;
}
| int MBMesquite::ParallelHelperImpl::comm_smoothed_vtx_b_no_all | ( | MsqError & | err | ) | [private] |
Definition at line 2471 of file ParallelHelper.cpp.
References ARRPTR, CHECK_MPI_RZERO, communicator, exportProc, exportVtxGIDs, exportVtxLIDs, iteration, mesh, MSQ_ERRZERO, neighbourProc, neighbourProcRecvRemain, neighbourProcSendRemain, num_exportVtx, part_smoothed_flag, part_vertices, rank, MBMesquite::Vector3D::set(), VERTEX_BLOCK, VERTEX_HEADER, MBMesquite::vertex_map_find(), MBMesquite::Mesh::vertex_set_coordinates(), MBMesquite::Mesh::vertices_get_coordinates(), vid_map, MBMesquite::Vector3D::y(), z, and MBMesquite::Vector3D::z().
Referenced by communicate_first_independent_set(), and communicate_next_independent_set().
{
int i, j, rval;
// printf("[%d] %d %d blocking avoid reduce all\n",rank, iteration, pass);fflush(NULL);
/* how many vertices per processor */
std::vector< int > numVtxPerProc( neighbourProc.size(), 0 );
for( i = 0; i < num_exportVtx; i++ )
{
for( j = 0; j < (long)neighbourProc.size(); j++ )
{
if( exportProc[i] == neighbourProc[j] )
{
/* increment count */
numVtxPerProc[j]++;
/* end loop */
break;
}
/* assert loop did not end without finding the processor */
assert( j != (long)neighbourProc.size() );
}
}
/* place vertices going to the same processor into consecutive memory space */
std::vector< VertexPack > vertex_pack( num_exportVtx + 10 ); /* add 10 to have enough memory */
std::vector< VertexPack* > packed_vertices( neighbourProc.size() );
VertexPack* packing_vertex;
packed_vertices[0] = ARRPTR( vertex_pack );
for( i = 1; i < (long)neighbourProc.size(); i++ )
{
packed_vertices[i] = packed_vertices[i - 1] + numVtxPerProc[i - 1];
}
std::vector< int > numVtxPackedPerProc( neighbourProc.size(), 0 );
for( i = 0; i < num_exportVtx; i++ )
{
for( j = 0; j < (long)neighbourProc.size(); j++ )
{
if( exportProc[i] == neighbourProc[j] )
{
packing_vertex = packed_vertices[j] + numVtxPackedPerProc[j];
numVtxPackedPerProc[j]++;
MBMesquite::MsqVertex coordinates;
mesh->vertices_get_coordinates( &part_vertices[exportVtxLIDs[i]], &coordinates, 1, err );
MSQ_ERRZERO( err );
packing_vertex->x = coordinates[0];
packing_vertex->y = coordinates[1];
packing_vertex->z = coordinates[2];
packing_vertex->glob_id = exportVtxGIDs[i];
}
}
}
// delete [] numVtxPackedPerProc;
/* send each block so the corresponding processor preceeded by the number of vertices */
for( j = 0; j < (long)neighbourProc.size(); j++ )
{
if( neighbourProcSendRemain[j] )
{
assert( neighbourProcSendRemain[j] >= numVtxPerProc[j] );
neighbourProcSendRemain[j] -= numVtxPerProc[j];
// printf("[%d]i%dp%d Announcing %d vertices to proc
// %d\n",rank,iteration,pass,numVtxPerProc[j],neighbourProc[j]); fflush(NULL);
rval = MPI_Send( &( numVtxPerProc[j] ), 1, MPI_INT, neighbourProc[j], VERTEX_HEADER + iteration,
(MPI_Comm)communicator );
CHECK_MPI_RZERO( rval, err );
// printf("[%d]i%dp%d Sending %d vertices to proc
// %d\n",rank,iteration,pass,numVtxPerProc[j],neighbourProc[j]); fflush(NULL);
/* is there any vertex data to be sent */
if( numVtxPerProc[j] )
{
rval = MPI_Send( packed_vertices[j], 4 * numVtxPerProc[j], MPI_DOUBLE, neighbourProc[j],
VERTEX_BLOCK + iteration, (MPI_Comm)communicator );
CHECK_MPI_RZERO( rval, err );
// printf("[%d]i%dp%d Sent %d vertices to proc
// %d\n",rank,iteration,pass,numVtxPerProc[j],neighbourProc[j]); fflush(NULL);
}
}
else
{
// printf("[%d]i%dp%d no longer sending to %d\n",rank,iteration,neighbourProc[j]);
// fflush(NULL);
}
}
int num;
int proc;
// int tag;
int count;
int numVtxImport = 0;
MPI_Status status;
int local_id;
// printf("[%d]i%dp%d Waiting to receive vertices from %d processors ...
// \n",rank,iteration,pass,neighbourProc.size()); fflush(NULL);
/* receiving blocks in any order from other processors */
int num_neighbourProcRecvRemain = 0;
for( j = 0; j < (long)neighbourProc.size(); j++ )
{
if( neighbourProcRecvRemain[j] )
{
num_neighbourProcRecvRemain++;
}
}
for( j = 0; j < num_neighbourProcRecvRemain; j++ )
{
rval = MPI_Recv( &num, /* message buffer */
1, /* one data item */
MPI_INT, /* of type int */
MPI_ANY_SOURCE, /* receive from any sender */
VERTEX_HEADER + iteration, /* receive only VERTEX HEADERs */
(MPI_Comm)communicator, /* default communicator */
&status ); /* info about the received message */
CHECK_MPI_RZERO( rval, err );
proc = status.MPI_SOURCE;
// tag = status.MPI_TAG;
MPI_Get_count( &status, MPI_INT, &count );
// printf("[%d]i%dp%d Receiving %d vertices from proc
// %d/%d/%d\n",rank,iteration,pass,num,proc,tag,count); fflush(NULL);
/* is there any vertex data to be received */
if( num )
{
numVtxImport += num;
/* do we have enough space allocated */
if( num_exportVtx + 10 < num )
{
// if (vertex_pack) free(vertex_pack);
num_exportVtx = num;
// vertex_pack = (VertexPack*)malloc(sizeof(VertexPack)*(num_exportVtx+10));
vertex_pack.resize( num_exportVtx + 10 );
}
rval = MPI_Recv( ARRPTR( vertex_pack ), /* message buffer */
4 * num, /* num data's item with 4 doubles each */
MPI_DOUBLE, /* of type double */
proc, /* receive from this procesor only */
VERTEX_BLOCK + iteration, /* receive only VERTEX BLOCKs */
(MPI_Comm)communicator, /* default communicator */
&status ); /* info about the received message */
CHECK_MPI_RZERO( rval, err );
proc = status.MPI_SOURCE;
// tag = status.MPI_TAG;
MPI_Get_count( &status, MPI_DOUBLE, &count );
if( count != 4 * num )
printf( "[%d]i%d WARNING: expected %d vertices = %d bytes from proc %d but only "
"got %d bytes\n",
rank, iteration, num, num * 4, proc, count );
fflush( NULL );
// printf("[%d]i%d Received %d vertices from proc
// %d/%d/%d\n",rank,iteration,num,proc,tag,count); fflush(NULL);
/* update the received vertices in our boundary mesh */
for( i = 0; i < num; i++ )
{
/* printf("[%d]i%d updating vertex %d with global_id
* %d\n",rank,iteration,i,(int)(vertex_pack[i].glob_id)); fflush(NULL); */
local_id = vertex_map_find( vid_map, (int)( vertex_pack[i].glob_id ), proc );
if( local_id )
{
MBMesquite::Vector3D coordinates;
coordinates.set( vertex_pack[i].x, vertex_pack[i].y, vertex_pack[i].z );
mesh->vertex_set_coordinates( part_vertices[local_id], coordinates, err );
MSQ_ERRZERO( err );
assert( part_smoothed_flag[local_id] == 0 );
part_smoothed_flag[local_id] = 1;
if( 0 && rank == 1 )
printf( "[%d]i%d updating vertex with global_id %d to %g %g %g \n", rank, iteration,
(int)( vertex_pack[i].glob_id ), vertex_pack[i].x, vertex_pack[i].y, vertex_pack[i].z );
}
else
{
printf( "[%d]i%d vertex with gid %lu and pid %d not in map\n", rank, iteration,
vertex_pack[i].glob_id, proc );
}
}
}
for( i = 0; i < (long)neighbourProc.size(); i++ )
{
if( proc == neighbourProc[i] )
{
assert( neighbourProcRecvRemain[i] >= num );
neighbourProcRecvRemain[i] -= num;
break;
}
}
}
// if (vertex_pack) free(vertex_pack);
return numVtxImport;
}
| int MBMesquite::ParallelHelperImpl::comm_smoothed_vtx_nb | ( | MsqError & | err | ) | [private] |
Definition at line 1797 of file ParallelHelper.cpp.
References ARRPTR, CHECK_MPI_RZERO, communicator, exportProc, exportVtxGIDs, exportVtxLIDs, MBMesquite::VertexPack::glob_id, iteration, mesh, MSQ_ERRZERO, neighbourProc, neighbourProcRecv, num_exportVtx, part_smoothed_flag, part_vertices, rank, MBMesquite::Vector3D::set(), VERTEX_BLOCK, VERTEX_HEADER, MBMesquite::vertex_map_find(), MBMesquite::Mesh::vertex_set_coordinates(), MBMesquite::Mesh::vertices_get_coordinates(), vid_map, MBMesquite::VertexPack::x, MBMesquite::VertexPack::y, z, and MBMesquite::VertexPack::z.
Referenced by communicate_first_independent_set(), and communicate_next_independent_set().
{
int i, j, k, rval;
// printf("[%d] %d %d non blocking\n",rank, iteration, pass);fflush(NULL);
/* how many vertices will we receive */
std::vector< int > numVtxPerProcSend( neighbourProc.size() );
for( i = 0; i < (long)neighbourProc.size(); i++ )
{
numVtxPerProcSend[i] = 0;
}
for( i = 0; i < num_exportVtx; i++ )
{
for( j = 0; j < (long)neighbourProc.size(); j++ )
{
if( exportProc[i] == neighbourProc[j] )
{
/* increment count */
numVtxPerProcSend[j]++;
/* end loop */
break;
}
}
/* assert loop did not end without finding processor */
assert( j != (long)neighbourProc.size() );
}
/* tell each processor how many vertices to expect */
for( j = 0; j < (long)neighbourProc.size(); j++ )
{
rval = MPI_Send( &( numVtxPerProcSend[j] ), 1, MPI_INT, neighbourProc[j], VERTEX_HEADER + iteration,
(MPI_Comm)communicator );
CHECK_MPI_RZERO( rval, err );
// printf("[%d]i%d Announcing %d vertices to proc
// %d\n",rank,iteration,numVtxPerProcSend[j],neighbourProc[j]); fflush(NULL);
}
/* place vertex data going to the same processor into consecutive memory space */
std::vector< VertexPack > vertex_pack_export( num_exportVtx + 10 ); /* add 10 to have enough memory */
std::vector< VertexPack* > packed_vertices_export( neighbourProc.size() );
if( neighbourProc.size() ) packed_vertices_export[0] = ARRPTR( vertex_pack_export );
for( i = 1; i < (long)neighbourProc.size(); i++ )
{
packed_vertices_export[i] = packed_vertices_export[i - 1] + numVtxPerProcSend[i - 1];
}
std::vector< int > numVtxPerProcSendPACKED( neighbourProc.size(), 0 );
for( i = 0; i < num_exportVtx; i++ )
{
for( j = 0; j < (long)neighbourProc.size(); j++ )
{
if( exportProc[i] == neighbourProc[j] )
{
VertexPack* packing_vertex = packed_vertices_export[j] + numVtxPerProcSendPACKED[j];
numVtxPerProcSendPACKED[j]++;
MBMesquite::MsqVertex coordinates;
mesh->vertices_get_coordinates( &part_vertices[exportVtxLIDs[i]], &coordinates, 1, err );
MSQ_ERRZERO( err );
packing_vertex->x = coordinates[0];
packing_vertex->y = coordinates[1];
packing_vertex->z = coordinates[2];
packing_vertex->glob_id = exportVtxGIDs[i];
}
}
}
// delete [] numVtxPerProcSendPACKED;
/* now ask each processor how many vertices to expect */
int num;
int proc;
int numVtxImport = 0;
int num_neighbourProcRecv = 0;
std::vector< int > numVtxPerProcRecv( neighbourProc.size() );
MPI_Status status;
for( j = 0; j < (long)neighbourProc.size(); j++ )
{
numVtxPerProcRecv[j] = 0;
}
for( j = 0; j < (long)neighbourProc.size(); j++ )
{
/* get the vertex count for some processor */
rval = MPI_Recv( &num, /* message buffer */
1, /* one data item */
MPI_INT, /* of type int */
MPI_ANY_SOURCE, /* receive from any sender */
VERTEX_HEADER + iteration, /* receive only VERTEX HEADERs from this iteration */
(MPI_Comm)communicator, /* default communicator */
&status ); /* info about the received message */
CHECK_MPI_RZERO( rval, err );
proc = status.MPI_SOURCE;
/* will we import vertices from this processor */
// printf("[%d]i%d Heard we will receive %d vertices from proc
// %d\n",rank,iteration,num,proc); fflush(NULL);
if( num )
{
/* increase number of processors we will receive from */
num_neighbourProcRecv++;
/* add number of vertices we will receive to the import total */
numVtxImport += num;
}
/* find this processor in the list */
for( i = 0; i < (long)neighbourProc.size(); i++ )
{
if( neighbourProc[i] == proc )
{
numVtxPerProcRecv[i] = num;
break;
}
}
/* assert loop did not end without finding processor */
assert( i != (long)neighbourProc.size() );
if( 0 ) printf( "[%d]i%d Will receive %d vertices from proc %d\n", rank, iteration, num, proc );
fflush( NULL );
}
/* create list of processors we receive from */
std::vector< int > neighbourProcRecv( num_neighbourProcRecv );
std::vector< int > numVtxPerProcRecvRecv( num_neighbourProcRecv );
for( i = 0, k = 0; i < (long)neighbourProc.size(); i++ )
{
if( 0 )
printf( "[%d]i%d Will receive %d vertices from proc %d\n", rank, iteration, numVtxPerProcRecv[i],
neighbourProc[i] );
fflush( NULL );
if( numVtxPerProcRecv[i] )
{
neighbourProcRecv[k] = neighbourProc[i];
numVtxPerProcRecvRecv[k] = numVtxPerProcRecv[i];
k++;
}
}
/* set up memory for the incoming vertex data blocks */
std::vector< VertexPack > vertex_pack_import( numVtxImport + 10 ); /* add 10 to have enough memory */
std::vector< VertexPack* > packed_vertices_import( num_neighbourProcRecv );
if( neighbourProc.size() ) packed_vertices_import[0] = ARRPTR( vertex_pack_import );
for( i = 1; i < num_neighbourProcRecv; i++ )
{
packed_vertices_import[i] = packed_vertices_import[i - 1] + numVtxPerProcRecvRecv[i - 1];
}
/* receive from all processors that have something for us */
std::vector< MPI_Request > request( num_neighbourProcRecv );
for( j = 0; j < num_neighbourProcRecv; j++ )
{
rval = MPI_Irecv( packed_vertices_import[j], 4 * numVtxPerProcRecvRecv[j], MPI_DOUBLE, neighbourProcRecv[j],
VERTEX_BLOCK + iteration, (MPI_Comm)communicator, &( request[j] ) );
CHECK_MPI_RZERO( rval, err );
if( false )
{
printf( "[%d]i%d Scheduling receipt of %d vertices to proc %d\n", rank, iteration, numVtxPerProcRecvRecv[j],
neighbourProcRecv[j] );
fflush( NULL );
}
}
/* now send the data blocks */
std::vector< MPI_Request > requests_send( neighbourProc.size() );
for( j = 0; j < (long)neighbourProc.size(); j++ )
{
if( numVtxPerProcSend[j] )
{
rval = MPI_Isend( packed_vertices_export[j], 4 * numVtxPerProcSend[j], MPI_DOUBLE, neighbourProc[j],
VERTEX_BLOCK + iteration, (MPI_Comm)communicator, &( requests_send[j] ) );
CHECK_MPI_RZERO( rval, err );
if( 0 )
{
printf( "[%d]i%d Scheduling send of %d vertices to proc %d\n", rank, iteration, numVtxPerProcSend[j],
neighbourProc[j] );
fflush( NULL );
}
}
else
{
requests_send[j] = MPI_REQUEST_NULL;
}
}
/* process messages as they arrive */
int local_id;
for( j = 0; j < num_neighbourProcRecv; j++ )
{
rval = MPI_Waitany( num_neighbourProcRecv, ARRPTR( request ), &k, &status );
CHECK_MPI_RZERO( rval, err );
/* unpack messages */
proc = status.MPI_SOURCE;
int count;
MPI_Get_count( &status, MPI_INT, &count );
if( 0 )
printf( "[%d]i%d Received %d (%d) vertices from proc %d (%d)\n", rank, iteration, numVtxPerProcRecvRecv[k],
count, neighbourProcRecv[k], proc );
fflush( NULL );
for( i = 0; i < numVtxPerProcRecvRecv[k]; i++ )
{
local_id = vertex_map_find( vid_map, packed_vertices_import[k][i].glob_id, neighbourProcRecv[k] );
if( local_id )
{
MBMesquite::Vector3D coordinates;
coordinates.set( packed_vertices_import[k][i].x, packed_vertices_import[k][i].y,
packed_vertices_import[k][i].z );
mesh->vertex_set_coordinates( part_vertices[local_id], coordinates, err );
MSQ_ERRZERO( err );
assert( part_smoothed_flag[local_id] == 0 );
part_smoothed_flag[local_id] = 1;
if( 0 )
printf( "[%d]i%d updating vertex with global_id %d to %g %g %g \n", rank, iteration,
(int)( packed_vertices_import[k][i].glob_id ), packed_vertices_import[k][i].x,
packed_vertices_import[k][i].y, packed_vertices_import[k][i].z );
}
else
{
printf( "[%d]i%d vertex with gid %lu and pid %d not in map\n", rank, iteration,
packed_vertices_import[k][i].glob_id, neighbourProcRecv[k] );
}
}
}
/* all receives have completed. it is save to release the memory */
// free(vertex_pack_import);
/* wait until the sends have completed */
std::vector< MPI_Status > stati( neighbourProc.size() );
rval = MPI_Waitall( neighbourProc.size(), ARRPTR( requests_send ), ARRPTR( stati ) );
CHECK_MPI_RZERO( rval, err );
/* all sends have completed. it is save to release the memory */
// free(vertex_pack_export);
return numVtxImport;
}
| int MBMesquite::ParallelHelperImpl::comm_smoothed_vtx_nb_no_all | ( | MsqError & | err | ) | [private] |
Definition at line 2036 of file ParallelHelper.cpp.
References ARRPTR, CHECK_MPI_RZERO, communicator, exportProc, exportVtxGIDs, exportVtxLIDs, MBMesquite::VertexPack::glob_id, iteration, mesh, MSQ_ERRZERO, neighbourProc, neighbourProcRecv, neighbourProcRecvRemain, neighbourProcSendRemain, num_exportVtx, part_smoothed_flag, part_vertices, rank, MBMesquite::Vector3D::set(), VERTEX_BLOCK, VERTEX_HEADER, MBMesquite::vertex_map_find(), MBMesquite::Mesh::vertex_set_coordinates(), MBMesquite::Mesh::vertices_get_coordinates(), vid_map, MBMesquite::VertexPack::x, MBMesquite::VertexPack::y, z, and MBMesquite::VertexPack::z.
Referenced by communicate_first_independent_set(), and communicate_next_independent_set().
{
int i, j, k, rval;
// printf("[%d] %d %d non blocking avoid reduce all\n",rank, iteration, pass);fflush(NULL);
/* how many vertices will we receive */
std::vector< int > numVtxPerProcSend( neighbourProc.size(), 0 );
for( i = 0; i < num_exportVtx; i++ )
{
for( j = 0; j < (long)neighbourProc.size(); j++ )
{
if( exportProc[i] == neighbourProc[j] )
{
/* increment count */
numVtxPerProcSend[j]++;
/* end loop */
break;
}
}
/* assert loop did not end without finding processor */
assert( j != (long)neighbourProc.size() );
}
/* tell each processor how many vertices to expect */
for( j = 0; j < (long)neighbourProc.size(); j++ )
{
if( neighbourProcSendRemain[j] )
{
assert( neighbourProcSendRemain[j] >= numVtxPerProcSend[j] );
neighbourProcSendRemain[j] -= numVtxPerProcSend[j];
rval = MPI_Send( &( numVtxPerProcSend[j] ), 1, MPI_INT, neighbourProc[j], VERTEX_HEADER + iteration,
(MPI_Comm)communicator );
CHECK_MPI_RZERO( rval, err );
// printf("[%d]i%d Announcing %d vertices to proc
// %d\n",rank,iteration,numVtxPerProcSend[j],neighbourProc[j]); fflush(NULL);
}
else
{
assert( numVtxPerProcSend[j] == 0 );
}
}
/* place vertex data going to the same processor into consecutive memory space */
std::vector< VertexPack > vertex_pack_export( num_exportVtx + 10 ); /* add 10 to have enough memory */
std::vector< VertexPack* > packed_vertices_export( neighbourProc.size() );
if( neighbourProc.size() ) packed_vertices_export[0] = ARRPTR( vertex_pack_export );
for( i = 1; i < (long)neighbourProc.size(); i++ )
{
packed_vertices_export[i] = packed_vertices_export[i - 1] + numVtxPerProcSend[i - 1];
}
std::vector< int > numVtxPerProcSendPACKED( neighbourProc.size(), 0 );
for( i = 0; i < num_exportVtx; i++ )
{
for( j = 0; j < (long)neighbourProc.size(); j++ )
{
if( exportProc[i] == neighbourProc[j] )
{
VertexPack* packing_vertex = packed_vertices_export[j] + numVtxPerProcSendPACKED[j];
numVtxPerProcSendPACKED[j]++;
MBMesquite::MsqVertex coordinates;
mesh->vertices_get_coordinates( &part_vertices[exportVtxLIDs[i]], &coordinates, 1, err );
MSQ_ERRZERO( err );
packing_vertex->x = coordinates[0];
packing_vertex->y = coordinates[1];
packing_vertex->z = coordinates[2];
packing_vertex->glob_id = exportVtxGIDs[i];
}
}
}
// delete [] numVtxPerProcSendPACKED;
/* now ask each processor how many vertices to expect */
int num;
int proc;
int numVtxImport = 0;
int num_neighbourProcRecv = 0;
std::vector< int > numVtxPerProcRecv( neighbourProc.size(), 0 );
MPI_Status status;
int num_neighbourProcRecvRemain = 0;
for( j = 0; j < (long)neighbourProc.size(); j++ )
{
if( neighbourProcRecvRemain[j] )
{
num_neighbourProcRecvRemain++;
}
}
for( j = 0; j < num_neighbourProcRecvRemain; j++ )
{
/* get the vertex count for some processor */
rval = MPI_Recv( &num, /* message buffer */
1, /* one data item */
MPI_INT, /* of type int */
MPI_ANY_SOURCE, /* receive from any sender */
VERTEX_HEADER + iteration, /* receive only VERTEX HEADERs from this iteration */
(MPI_Comm)communicator, /* default communicator */
&status ); /* info about the received message */
CHECK_MPI_RZERO( rval, err );
proc = status.MPI_SOURCE;
/* will we import vertices from this processor */
// printf("[%d]i%d Heard we will receive %d vertices from proc
// %d\n",rank,iteration,num,proc); fflush(NULL);
if( num )
{
/* increase number of processors we will receive from */
num_neighbourProcRecv++;
/* add number of vertices we will receive to the import total */
numVtxImport += num;
}
/* find this processor in the list */
for( i = 0; i < (long)neighbourProc.size(); i++ )
{
if( neighbourProc[i] == proc )
{
numVtxPerProcRecv[i] = num;
assert( neighbourProcRecvRemain[i] >= num );
neighbourProcRecvRemain[i] -= num;
break;
}
}
/* assert loop did not end without finding processor */
assert( i != (long)neighbourProc.size() );
if( false ) printf( "[%d]i%d Will receive %d vertices from proc %d\n", rank, iteration, num, proc );
fflush( NULL );
}
/* create list of processors we receive from */
std::vector< int > neighbourProcRecv( num_neighbourProcRecv );
std::vector< int > numVtxPerProcRecvRecv( num_neighbourProcRecv );
for( i = 0, k = 0; i < (long)neighbourProc.size(); i++ )
{
if( 0 )
printf( "[%d]i%d Will receive %d vertices from proc %d\n", rank, iteration, numVtxPerProcRecv[i],
neighbourProc[i] );
fflush( NULL );
if( numVtxPerProcRecv[i] )
{
neighbourProcRecv[k] = neighbourProc[i];
numVtxPerProcRecvRecv[k] = numVtxPerProcRecv[i];
k++;
}
}
/* set up memory for the incoming vertex data blocks */
std::vector< VertexPack > vertex_pack_import( numVtxImport + 10 ); /* add 10 to have enough memory */
std::vector< VertexPack* > packed_vertices_import( num_neighbourProcRecv );
if( neighbourProc.size() ) packed_vertices_import[0] = ARRPTR( vertex_pack_import );
for( i = 1; i < num_neighbourProcRecv; i++ )
{
packed_vertices_import[i] = packed_vertices_import[i - 1] + numVtxPerProcRecvRecv[i - 1];
}
/* receive from all processors that have something for us */
std::vector< MPI_Request > request( num_neighbourProcRecv );
for( j = 0; j < num_neighbourProcRecv; j++ )
{
rval = MPI_Irecv( packed_vertices_import[j], 4 * numVtxPerProcRecvRecv[j], MPI_DOUBLE, neighbourProcRecv[j],
VERTEX_BLOCK + iteration, (MPI_Comm)communicator, &( request[j] ) );
CHECK_MPI_RZERO( rval, err );
if( false )
{
printf( "[%d]i%d Scheduling receipt of %d vertices to proc %d\n", rank, iteration, numVtxPerProcRecvRecv[j],
neighbourProcRecv[j] );
fflush( NULL );
}
}
/* now send the data blocks */
std::vector< MPI_Request > requests_send( neighbourProc.size() );
for( j = 0; j < (long)neighbourProc.size(); j++ )
{
if( numVtxPerProcSend[j] )
{
rval = MPI_Isend( packed_vertices_export[j], 4 * numVtxPerProcSend[j], MPI_DOUBLE, neighbourProc[j],
VERTEX_BLOCK + iteration, (MPI_Comm)communicator, &( requests_send[j] ) );
CHECK_MPI_RZERO( rval, err );
if( 0 )
{
printf( "[%d]i%d Scheduling send of %d vertices to proc %d\n", rank, iteration, numVtxPerProcSend[j],
neighbourProc[j] );
fflush( NULL );
}
}
else
{
requests_send[j] = MPI_REQUEST_NULL;
}
}
/* process messages as they arrive */
int local_id;
for( j = 0; j < num_neighbourProcRecv; j++ )
{
rval = MPI_Waitany( num_neighbourProcRecv, ARRPTR( request ), &k, &status );
CHECK_MPI_RZERO( rval, err );
/* unpack messages */
proc = status.MPI_SOURCE;
int count;
MPI_Get_count( &status, MPI_INT, &count );
if( 0 )
printf( "[%d]i%d Received %d (%d) vertices from proc %d (%d)\n", rank, iteration, numVtxPerProcRecvRecv[k],
count, neighbourProcRecv[k], proc );
fflush( NULL );
for( i = 0; i < numVtxPerProcRecvRecv[k]; i++ )
{
local_id = vertex_map_find( vid_map, packed_vertices_import[k][i].glob_id, neighbourProcRecv[k] );
if( local_id )
{
MBMesquite::Vector3D coordinates;
coordinates.set( packed_vertices_import[k][i].x, packed_vertices_import[k][i].y,
packed_vertices_import[k][i].z );
mesh->vertex_set_coordinates( part_vertices[local_id], coordinates, err );
MSQ_ERRZERO( err );
assert( part_smoothed_flag[local_id] == 0 );
part_smoothed_flag[local_id] = 1;
if( 0 )
printf( "[%d]i%d updating vertex with global_id %d to %g %g %g \n", rank, iteration,
(int)( packed_vertices_import[k][i].glob_id ), packed_vertices_import[k][i].x,
packed_vertices_import[k][i].y, packed_vertices_import[k][i].z );
}
else
{
printf( "[%d]i%d vertex with gid %lu and pid %d not in map\n", rank, iteration,
packed_vertices_import[k][i].glob_id, neighbourProcRecv[k] );
}
}
}
/* all receives have completed. it is save to release the memory */
// free(vertex_pack_import);
/* wait until the sends have completed */
std::vector< MPI_Status > stati( neighbourProc.size() );
rval = MPI_Waitall( neighbourProc.size(), ARRPTR( requests_send ), ARRPTR( stati ) );
CHECK_MPI_RZERO( rval, err );
/* all sends have completed. it is save to release the memory */
// free(vertex_pack_export);
return numVtxImport;
}
| int MBMesquite::ParallelHelperImpl::comm_smoothed_vtx_tnb | ( | MsqError & | err | ) | [private] |
Definition at line 1346 of file ParallelHelper.cpp.
References ARRPTR, CHECK_MPI_RZERO, communicator, exportProc, exportVtxGIDs, exportVtxLIDs, MBMesquite::VertexPack::glob_id, iteration, mesh, MSQ_ERRZERO, neighbourProc, num_exportVtx, part_smoothed_flag, part_vertices, rank, MBMesquite::Vector3D::set(), VERTEX_BLOCK, VERTEX_HEADER, MBMesquite::vertex_map_find(), MBMesquite::Mesh::vertex_set_coordinates(), MBMesquite::Mesh::vertices_get_coordinates(), vid_map, MBMesquite::VertexPack::x, MBMesquite::VertexPack::y, z, and MBMesquite::VertexPack::z.
Referenced by communicate_first_independent_set(), and communicate_next_independent_set().
{
int i, j, k, rval;
// printf("[%d]i%d truly non blocking\n",rank, iteration);fflush(NULL);
/* compute how many vertices we send to each processor */
std::vector< int > numVtxPerProcSend( neighbourProc.size(), 0 );
std::vector< int > numVtxPerProcRecv( neighbourProc.size(), 0 );
for( i = 0; i < num_exportVtx; i++ )
{
for( j = 0; j < (long)neighbourProc.size(); j++ )
{
if( exportProc[i] == neighbourProc[j] )
{
/* increment count */
numVtxPerProcSend[j]++;
/* end loop */
break;
}
}
/* did loop end without finding the processor */
if( j == (long)neighbourProc.size() )
{
printf( "[%d]i%d WARNING: did not find exportProc[%d] = %d in list of %lu processors.\n", rank, iteration,
i, exportProc[i], (unsigned long)neighbourProc.size() );
}
}
/* tell each processor how many vertices they can expect from us */
/* also ask each processor how many vertices we can expect from them */
int num_neighbourProcSend = 0;
int num_neighbourProcRecv = 0;
std::vector< MPI_Request > requests_send( neighbourProc.size() );
std::vector< MPI_Request > requests_recv( neighbourProc.size() );
for( j = 0; j < (long)neighbourProc.size(); j++ )
{
/* send the vertex count to this processor */
if( 0 )
{
printf( "[%d]i%d Announce send %d vertices from proc %d\n", rank, iteration, numVtxPerProcSend[j],
neighbourProc[j] );
fflush( NULL );
}
rval = MPI_Isend( &( numVtxPerProcSend[j] ), 1, MPI_INT, neighbourProc[j], VERTEX_HEADER + iteration,
(MPI_Comm)communicator, &( requests_send[j] ) );
CHECK_MPI_RZERO( rval, err );
num_neighbourProcSend++;
/* recv the vertex count for this processor */
if( 0 )
{
printf( "[%d]i%d Listen recv %d vertices from proc %d\n", rank, iteration, numVtxPerProcRecv[j],
neighbourProc[j] );
fflush( NULL );
}
rval = MPI_Irecv( &( numVtxPerProcRecv[j] ), 1, MPI_INT, neighbourProc[j], VERTEX_HEADER + iteration,
(MPI_Comm)communicator, &( requests_recv[j] ) );
CHECK_MPI_RZERO( rval, err );
num_neighbourProcRecv++;
}
/* set up memory for the outgoing vertex data blocks */
std::vector< VertexPack > vertex_pack_export( num_exportVtx + 10 ); /* add 10 to have enough memory */
std::vector< VertexPack* > packed_vertices_export( neighbourProc.size() );
if( neighbourProc.size() ) packed_vertices_export[0] = ARRPTR( vertex_pack_export );
for( i = 1; i < (long)neighbourProc.size(); i++ )
{
packed_vertices_export[i] = packed_vertices_export[i - 1] + numVtxPerProcSend[i - 1];
}
/* place vertex data going to the same processor into consecutive memory space */
std::vector< int > numVtxPerProcSendPACKED( neighbourProc.size() );
for( i = 0; i < (long)neighbourProc.size(); i++ )
{
numVtxPerProcSendPACKED[i] = 0;
}
for( i = 0; i < num_exportVtx; i++ )
{
for( j = 0; j < (long)neighbourProc.size(); j++ )
{
if( exportProc[i] == neighbourProc[j] )
{
VertexPack* packing_vertex = packed_vertices_export[j] + numVtxPerProcSendPACKED[j];
numVtxPerProcSendPACKED[j]++;
MBMesquite::MsqVertex coordinates;
mesh->vertices_get_coordinates( &part_vertices[exportVtxLIDs[i]], &coordinates, 1, err );
MSQ_ERRZERO( err );
packing_vertex->x = coordinates[0];
packing_vertex->y = coordinates[1];
packing_vertex->z = coordinates[2];
packing_vertex->glob_id = exportVtxGIDs[i];
}
}
}
/* wait until we have heard from all processors how many vertices we will receive from them */
std::vector< MPI_Status > status( neighbourProc.size() );
if( num_neighbourProcRecv )
{
rval = MPI_Waitall( neighbourProc.size(), ARRPTR( requests_recv ), ARRPTR( status ) );
CHECK_MPI_RZERO( rval, err );
}
/* how many vertices will we receive */
int numVtxImport = 0;
for( i = 0; i < (long)neighbourProc.size(); i++ )
{
numVtxImport += numVtxPerProcRecv[i];
}
/* set up memory for the incoming vertex data blocks */
std::vector< VertexPack > vertex_pack_import( numVtxImport + 10 ); /* add 10 to have enough memory */
std::vector< VertexPack* > packed_vertices_import( neighbourProc.size() );
if( neighbourProc.size() ) packed_vertices_import[0] = ARRPTR( vertex_pack_import );
for( i = 1; i < (long)neighbourProc.size(); i++ )
{
packed_vertices_import[i] = packed_vertices_import[i - 1] + numVtxPerProcRecv[i - 1];
}
/* post receives for all processors that have something for us */
/* post sends for all processors that we have something for */
num_neighbourProcRecv = 0;
for( i = 0; i < (long)neighbourProc.size(); i++ )
{
if( numVtxPerProcRecv[i] )
{
if( 0 )
{
printf( "[%d]i%d Will recv %d vertices from proc %d\n", rank, iteration, numVtxPerProcRecv[i],
neighbourProc[i] );
fflush( NULL );
}
rval = MPI_Irecv( packed_vertices_import[i], 4 * numVtxPerProcRecv[i], MPI_DOUBLE, neighbourProc[i],
VERTEX_BLOCK + iteration, (MPI_Comm)communicator, &( requests_recv[i] ) );
CHECK_MPI_RZERO( rval, err );
num_neighbourProcRecv++;
}
else
{
requests_recv[i] = MPI_REQUEST_NULL;
}
if( numVtxPerProcSend[i] )
{
if( 0 )
{
printf( "[%d]i%d Will send %d vertices to proc %d\n", rank, iteration, numVtxPerProcSend[i],
neighbourProc[i] );
fflush( NULL );
}
rval = MPI_Isend( packed_vertices_export[i], 4 * numVtxPerProcSend[i], MPI_DOUBLE, neighbourProc[i],
VERTEX_BLOCK + iteration, (MPI_Comm)communicator, &( requests_send[i] ) );
CHECK_MPI_RZERO( rval, err );
}
else
{
requests_send[i] = MPI_REQUEST_NULL;
}
}
/* wait for some receive to arrive */
int local_id;
while( num_neighbourProcRecv )
{
rval = MPI_Waitany( neighbourProc.size(), ARRPTR( requests_recv ), &k, ARRPTR( status ) );
CHECK_MPI_RZERO( rval, err );
/* unpack all vertices */
for( i = 0; i < numVtxPerProcRecv[k]; i++ )
{
local_id = vertex_map_find( vid_map, packed_vertices_import[k][i].glob_id, neighbourProc[k] );
if( local_id )
{
MBMesquite::Vector3D coordinates;
coordinates.set( packed_vertices_import[k][i].x, packed_vertices_import[k][i].y,
packed_vertices_import[k][i].z );
mesh->vertex_set_coordinates( part_vertices[local_id], coordinates, err );
MSQ_ERRZERO( err );
assert( part_smoothed_flag[local_id] == 0 );
part_smoothed_flag[local_id] = 1;
}
else
{
printf( "[%d]i%d vertex with gid %lu and pid %d not in map\n", rank, iteration,
packed_vertices_import[k][i].glob_id, neighbourProc[k] );
}
}
num_neighbourProcRecv--;
}
/* all receives have completed. it is save to release the memory */
// free(vertex_pack_import);
/* wait until the sends have completed */
if( num_neighbourProcSend )
{
rval = MPI_Waitall( neighbourProc.size(), ARRPTR( requests_send ), ARRPTR( status ) );
CHECK_MPI_RZERO( rval, err );
}
/* all sends have completed. it is save to release the memory */
// free(vertex_pack_export);
return numVtxImport;
}
| int MBMesquite::ParallelHelperImpl::comm_smoothed_vtx_tnb_no_all | ( | MsqError & | err | ) | [private] |
Definition at line 1563 of file ParallelHelper.cpp.
References ARRPTR, CHECK_MPI_RZERO, communicator, exportProc, exportVtxGIDs, exportVtxLIDs, MBMesquite::VertexPack::glob_id, iteration, mesh, MSQ_ERRZERO, neighbourProc, neighbourProcRecvRemain, neighbourProcSendRemain, num_exportVtx, part_smoothed_flag, part_vertices, rank, MBMesquite::Vector3D::set(), VERTEX_BLOCK, VERTEX_HEADER, MBMesquite::vertex_map_find(), MBMesquite::Mesh::vertex_set_coordinates(), MBMesquite::Mesh::vertices_get_coordinates(), vid_map, MBMesquite::VertexPack::x, MBMesquite::VertexPack::y, z, and MBMesquite::VertexPack::z.
Referenced by communicate_first_independent_set(), and communicate_next_independent_set().
{
int i, j, k, rval;
// printf("[%d]i%d truly non blocking avoid reduce all\n", rank, iteration); fflush(NULL);
/* compute how many vertices we send to each processor */
std::vector< int > numVtxPerProcSend( neighbourProc.size(), 0 );
std::vector< int > numVtxPerProcRecv( neighbourProc.size(), 0 );
for( i = 0; i < num_exportVtx; i++ )
{
for( j = 0; j < (long)neighbourProc.size(); j++ )
{
if( exportProc[i] == neighbourProc[j] )
{
/* increment count */
numVtxPerProcSend[j]++;
/* end loop */
break;
}
}
/* did loop end without finding the processor */
if( j == (long)neighbourProc.size() )
{
printf( "[%d]i%d WARNING: did not find exportProc[%d] = %d in list of %lu processors.\n", rank, iteration,
i, exportProc[i], (unsigned long)neighbourProc.size() );
}
}
/* tell each processor how many vertices they can expect from us */
/* also ask each processor how many vertices we can expect from them */
int num_neighbourProcSend = 0;
int num_neighbourProcRecv = 0;
std::vector< MPI_Request > requests_send( neighbourProc.size() );
std::vector< MPI_Request > requests_recv( neighbourProc.size() );
for( j = 0; j < (long)neighbourProc.size(); j++ )
{
if( neighbourProcSendRemain[j] )
{
/* send the vertex count to this processor */
if( 0 )
{
printf( "[%d]i%d Announce send %d vertices to proc %d\n", rank, iteration, numVtxPerProcSend[j],
neighbourProc[j] );
fflush( NULL );
}
rval = MPI_Isend( &( numVtxPerProcSend[j] ), 1, MPI_INT, neighbourProc[j], VERTEX_HEADER + iteration,
(MPI_Comm)communicator, &( requests_send[j] ) );
CHECK_MPI_RZERO( rval, err );
num_neighbourProcSend++;
}
else
{
requests_send[j] = MPI_REQUEST_NULL;
}
if( neighbourProcRecvRemain[j] )
{
/* recv the vertex count for this processor */
if( 0 )
{
printf( "[%d]i%d Listen recv xx vertices from proc %d\n", rank, iteration, neighbourProc[j] );
fflush( NULL );
}
rval = MPI_Irecv( &( numVtxPerProcRecv[j] ), 1, MPI_INT, neighbourProc[j], VERTEX_HEADER + iteration,
(MPI_Comm)communicator, &( requests_recv[j] ) );
CHECK_MPI_RZERO( rval, err );
num_neighbourProcRecv++;
}
else
{
requests_recv[j] = MPI_REQUEST_NULL;
}
}
/* set up memory for the outgoing vertex data blocks */
std::vector< VertexPack > vertex_pack_export( num_exportVtx + 10 ); /* add 10 to have enough memory */
std::vector< VertexPack* > packed_vertices_export( neighbourProc.size() );
if( neighbourProc.size() ) packed_vertices_export[0] = ARRPTR( vertex_pack_export );
for( i = 1; i < (long)neighbourProc.size(); i++ )
{
packed_vertices_export[i] = packed_vertices_export[i - 1] + numVtxPerProcSend[i - 1];
}
/* place vertex data going to the same processor into consecutive memory space */
std::vector< int > numVtxPerProcSendPACKED( neighbourProc.size(), 0 );
for( i = 0; i < num_exportVtx; i++ )
{
for( j = 0; j < (long)neighbourProc.size(); j++ )
{
if( exportProc[i] == neighbourProc[j] )
{
VertexPack* packing_vertex = packed_vertices_export[j] + numVtxPerProcSendPACKED[j];
numVtxPerProcSendPACKED[j]++;
MBMesquite::MsqVertex coordinates;
mesh->vertices_get_coordinates( &part_vertices[exportVtxLIDs[i]], &coordinates, 1, err );
MSQ_ERRZERO( err );
packing_vertex->x = coordinates[0];
packing_vertex->y = coordinates[1];
packing_vertex->z = coordinates[2];
packing_vertex->glob_id = exportVtxGIDs[i];
if( 0 )
printf( "[%d]i%d vertex %lu packed %g %g %g\n", rank, iteration, (unsigned long)exportVtxGIDs[i],
packing_vertex->x, packing_vertex->y, packing_vertex->z );
}
}
}
/* wait until we have heard from all processors how many vertices we will receive from them */
std::vector< MPI_Status > status( neighbourProc.size() );
if( num_neighbourProcRecv )
{
rval = MPI_Waitall( neighbourProc.size(), ARRPTR( requests_recv ), ARRPTR( status ) );
CHECK_MPI_RZERO( rval, err );
}
/* how many vertices will we receive */
int numVtxImport = 0;
for( i = 0; i < (long)neighbourProc.size(); i++ )
{
numVtxImport += numVtxPerProcRecv[i];
neighbourProcRecvRemain[i] -= numVtxPerProcRecv[i];
neighbourProcSendRemain[i] -= numVtxPerProcSend[i];
}
/* set up memory for the incoming vertex data blocks */
std::vector< VertexPack > vertex_pack_import( numVtxImport + 10 ); /* add 10 to have enough memory */
std::vector< VertexPack* > packed_vertices_import( neighbourProc.size() );
if( neighbourProc.size() ) packed_vertices_import[0] = ARRPTR( vertex_pack_import );
for( i = 1; i < (long)neighbourProc.size(); i++ )
{
packed_vertices_import[i] = packed_vertices_import[i - 1] + numVtxPerProcRecv[i - 1];
}
/* post receives for all processors that have something for us */
/* post sends for all processors that we have something for */
num_neighbourProcRecv = 0;
for( i = 0; i < (long)neighbourProc.size(); i++ )
{
if( 0 )
{
printf( "[%d]i%d Will recv %d vertices from proc %d\n", rank, iteration, numVtxPerProcRecv[i],
neighbourProc[i] );
fflush( NULL );
}
if( numVtxPerProcRecv[i] )
{
rval = MPI_Irecv( packed_vertices_import[i], 4 * numVtxPerProcRecv[i], MPI_DOUBLE, neighbourProc[i],
VERTEX_BLOCK + iteration, (MPI_Comm)communicator, &( requests_recv[i] ) );
CHECK_MPI_RZERO( rval, err );
num_neighbourProcRecv++;
}
else
{
requests_recv[i] = MPI_REQUEST_NULL;
}
if( 0 )
{
printf( "[%d]i%d Will send %d vertices to proc %d\n", rank, iteration, numVtxPerProcSend[i],
neighbourProc[i] );
fflush( NULL );
}
if( numVtxPerProcSend[i] )
{
rval = MPI_Isend( packed_vertices_export[i], 4 * numVtxPerProcSend[i], MPI_DOUBLE, neighbourProc[i],
VERTEX_BLOCK + iteration, (MPI_Comm)communicator, &( requests_send[i] ) );
CHECK_MPI_RZERO( rval, err );
}
else
{
requests_send[i] = MPI_REQUEST_NULL;
}
}
/* wait for some receive to arrive */
int local_id;
while( num_neighbourProcRecv )
{
rval = MPI_Waitany( neighbourProc.size(), ARRPTR( requests_recv ), &k, ARRPTR( status ) );
CHECK_MPI_RZERO( rval, err );
/* unpack all vertices */
for( i = 0; i < numVtxPerProcRecv[k]; i++ )
{
local_id = vertex_map_find( vid_map, packed_vertices_import[k][i].glob_id, neighbourProc[k] );
if( local_id )
{
MBMesquite::Vector3D coordinates;
coordinates.set( packed_vertices_import[k][i].x, packed_vertices_import[k][i].y,
packed_vertices_import[k][i].z );
if( 0 )
printf( "[%d]i%d vertex %d becomes %g %g %g\n", rank, iteration, local_id,
packed_vertices_import[k][i].x, packed_vertices_import[k][i].y,
packed_vertices_import[k][i].z );
mesh->vertex_set_coordinates( part_vertices[local_id], coordinates, err );
MSQ_ERRZERO( err );
assert( part_smoothed_flag[local_id] == 0 );
part_smoothed_flag[local_id] = 1;
}
else
{
printf( "[%d]i%d vertex with gid %lu and pid %d not in map\n", rank, iteration,
packed_vertices_import[k][i].glob_id, neighbourProc[k] );
}
}
num_neighbourProcRecv--;
}
/* all receives have completed. it is save to release the memory */
// free(vertex_pack_import);
/* wait until the sends have completed */
if( num_neighbourProcSend )
{
rval = MPI_Waitall( neighbourProc.size(), ARRPTR( requests_send ), ARRPTR( status ) );
CHECK_MPI_RZERO( rval, err );
}
/* all sends have completed. it is save to release the memory */
// free(vertex_pack_export);
return numVtxImport;
}
| void MBMesquite::ParallelHelperImpl::communicate_all_true | ( | bool & | value, |
| MsqError & | err | ||
| ) | const [protected, virtual] |
srkenno AT sandia.gov 1/19/12: bug fix: changed from MPI_MAX to MIN - this makes the name of the function correct, if all proc's values are true, it returns true.
| value | if all procs have value=true, else if any have it false, return false |
Implements MBMesquite::ParallelHelper.
Definition at line 2941 of file ParallelHelper.cpp.
References CHECK_MPI, communicator, and value().
{
int byte_out = value, byte_in;
int rval = MPI_Allreduce( &byte_out, &byte_in, 1, MPI_INT, MPI_MIN, (MPI_Comm)communicator );
CHECK_MPI( rval, err );
value = ( byte_in != 0 );
}
| void MBMesquite::ParallelHelperImpl::communicate_any_true | ( | bool & | value, |
| MsqError & | err | ||
| ) | const [protected, virtual] |
if any proc has a true input
| value,return | true to all |
Implements MBMesquite::ParallelHelper.
Definition at line 2927 of file ParallelHelper.cpp.
References CHECK_MPI, communicator, and value().
{
int byte_out = value, byte_in;
int rval = MPI_Allreduce( &byte_out, &byte_in, 1, MPI_INT, MPI_MAX, (MPI_Comm)communicator );
CHECK_MPI( rval, err );
value = ( byte_in != 0 );
}
| void MBMesquite::ParallelHelperImpl::communicate_first_independent_set | ( | MsqError & | err | ) | [protected, virtual] |
Implements MBMesquite::ParallelHelper.
Definition at line 1045 of file ParallelHelper.cpp.
References Blocking, BlockingAvoidAllReduce, comm_smoothed_vtx_b(), comm_smoothed_vtx_b_no_all(), comm_smoothed_vtx_nb(), comm_smoothed_vtx_nb_no_all(), comm_smoothed_vtx_tnb(), comm_smoothed_vtx_tnb_no_all(), communication_model, global_work_remains, MSQ_CHKERR, neighbourProc, NonBlocking, NonBlockingAvoidAllReduce, nprocs, num_already_recv_vertices, TrulyNonBlocking, and TrulyNonBlockingAvoidAllReduce.
{
if( nprocs == 1 ) return;
switch( communication_model )
{
case TrulyNonBlocking:
num_already_recv_vertices = comm_smoothed_vtx_tnb( err );
break;
case TrulyNonBlockingAvoidAllReduce:
num_already_recv_vertices = comm_smoothed_vtx_tnb_no_all( err );
break;
case NonBlocking:
num_already_recv_vertices = comm_smoothed_vtx_nb( err );
break;
case NonBlockingAvoidAllReduce:
num_already_recv_vertices = comm_smoothed_vtx_nb_no_all( err );
break;
case Blocking:
num_already_recv_vertices = comm_smoothed_vtx_b( err );
break;
case BlockingAvoidAllReduce:
num_already_recv_vertices = comm_smoothed_vtx_b_no_all( err );
break;
}
global_work_remains = ( neighbourProc.size() ? 1 : 0 );MSQ_CHKERR( err );
}
| void MBMesquite::ParallelHelperImpl::communicate_histogram_to_zero | ( | std::vector< int > & | histogram, |
| MsqError & | err | ||
| ) | const [protected, virtual] |
Implements MBMesquite::ParallelHelper.
Definition at line 2914 of file ParallelHelper.cpp.
References CHECK_MPI, communicator, and rank.
{
std::vector< int > histogram_recv( histogram.size() );
int rval = MPI_Reduce( &( histogram[0] ), &( histogram_recv[0] ), histogram.size(), MPI_INT, MPI_SUM, 0,
(MPI_Comm)communicator );
CHECK_MPI( rval, err );
if( rank == 0 )
{
histogram.swap( histogram_recv );
}
}
| void MBMesquite::ParallelHelperImpl::communicate_min_max_to_all | ( | double * | minimum, |
| double * | maximum, | ||
| MsqError & | err | ||
| ) | const [protected, virtual] |
Implements MBMesquite::ParallelHelper.
Definition at line 2838 of file ParallelHelper.cpp.
References CHECK_MPI, and communicator.
{
double d_min[2];
double d_min_recv[2];
d_min[0] = -( *maximum );
d_min[1] = *minimum;
int rval = MPI_Allreduce( d_min, d_min_recv, 2, MPI_DOUBLE, MPI_MIN, (MPI_Comm)communicator );
CHECK_MPI( rval, err );
*maximum = -d_min_recv[0];
*minimum = d_min_recv[1];
}
| void MBMesquite::ParallelHelperImpl::communicate_min_max_to_zero | ( | double * | minimum, |
| double * | maximum, | ||
| MsqError & | err | ||
| ) | const [protected, virtual] |
Implements MBMesquite::ParallelHelper.
Definition at line 2850 of file ParallelHelper.cpp.
References CHECK_MPI, communicator, and rank.
{
double d_min[2];
double d_min_recv[2];
d_min[0] = -( *maximum );
d_min[1] = *minimum;
int rval = MPI_Reduce( d_min, d_min_recv, 2, MPI_DOUBLE, MPI_MIN, 0, (MPI_Comm)communicator );
CHECK_MPI( rval, err );
if( rank == 0 )
{
*maximum = -d_min_recv[0];
*minimum = d_min_recv[1];
}
}
| void MBMesquite::ParallelHelperImpl::communicate_next_independent_set | ( | MsqError & | err | ) | [protected, virtual] |
Implements MBMesquite::ParallelHelper.
Definition at line 1119 of file ParallelHelper.cpp.
References Blocking, BlockingAvoidAllReduce, CHECK_MPI, comm_smoothed_vtx_b(), comm_smoothed_vtx_b_no_all(), comm_smoothed_vtx_nb(), comm_smoothed_vtx_nb_no_all(), comm_smoothed_vtx_tnb(), comm_smoothed_vtx_tnb_no_all(), communication_model, communicator, global_work_remains, iteration, NonBlocking, NonBlockingAvoidAllReduce, num_already_recv_vertices, num_already_smoothed_vertices, num_vtx_partition_boundary_local, part_smoothed_flag, rank, total_num_vertices_to_recv, total_num_vertices_to_smooth, TrulyNonBlocking, and TrulyNonBlockingAvoidAllReduce.
{
switch( communication_model )
{
case TrulyNonBlocking:
num_already_recv_vertices += comm_smoothed_vtx_tnb( err );
break;
case TrulyNonBlockingAvoidAllReduce:
num_already_recv_vertices += comm_smoothed_vtx_tnb_no_all( err );
break;
case NonBlocking:
num_already_recv_vertices += comm_smoothed_vtx_nb( err );
break;
case NonBlockingAvoidAllReduce:
num_already_recv_vertices += comm_smoothed_vtx_nb_no_all( err );
break;
case Blocking:
num_already_recv_vertices += comm_smoothed_vtx_b( err );
break;
case BlockingAvoidAllReduce:
num_already_recv_vertices += comm_smoothed_vtx_b_no_all( err );
break;
}
if( communication_model & 1 ) // AVOID_ALL_REDUCE
{
global_work_remains = ( total_num_vertices_to_smooth - num_already_smoothed_vertices ) +
( total_num_vertices_to_recv - num_already_recv_vertices );
if( false )
{
printf( "[%d]i%d %d - %d + %d - %d = %d \n", rank, iteration, total_num_vertices_to_smooth,
num_already_smoothed_vertices, total_num_vertices_to_recv, num_already_recv_vertices,
global_work_remains );
fflush( NULL );
}
}
else
{
int i, work_remains = 0;
for( i = 0; i < num_vtx_partition_boundary_local; i++ )
{
if( part_smoothed_flag[i] == 0 )
{
work_remains++;
}
}
int rval = MPI_Allreduce( &work_remains, &global_work_remains, 1, MPI_INT, MPI_SUM, (MPI_Comm)communicator );
CHECK_MPI( rval, err );
}
}
| void MBMesquite::ParallelHelperImpl::communicate_power_sum_to_zero | ( | double * | pMean, |
| MsqError & | err | ||
| ) | const [protected, virtual] |
Implements MBMesquite::ParallelHelper.
Definition at line 2906 of file ParallelHelper.cpp.
References CHECK_MPI, communicator, and rank.
{
double result;
int rval = MPI_Reduce( pMean, &result, 1, MPI_DOUBLE, MPI_SUM, 0, (MPI_Comm)communicator );
CHECK_MPI( rval, err );
if( rank == 0 ) *pMean = result;
}
| void MBMesquite::ParallelHelperImpl::communicate_sums_to_zero | ( | size_t * | freeElementCount, |
| int * | invertedElementCount, | ||
| size_t * | elementCount, | ||
| int * | invertedSampleCount, | ||
| size_t * | sampleCount, | ||
| long unsigned int * | count, | ||
| long unsigned int * | invalid, | ||
| double * | sum, | ||
| double * | sqrSum, | ||
| MsqError & | err | ||
| ) | const [protected, virtual] |
Implements MBMesquite::ParallelHelper.
Definition at line 2865 of file ParallelHelper.cpp.
References CHECK_MPI, communicator, rank, and moab::sum().
{
double d_sum[9];
double d_sum_recv[9];
d_sum[0] = (double)( *freeElementCount );
d_sum[1] = (double)( *invertedElementCount );
d_sum[2] = (double)( *elementCount );
d_sum[3] = (double)( *invertedSampleCount );
d_sum[4] = (double)( *sampleCount );
d_sum[5] = (double)( *count );
d_sum[6] = (double)( *invalid );
d_sum[7] = *sum;
d_sum[8] = *sqrSum;
int rval = MPI_Reduce( d_sum, d_sum_recv, 9, MPI_DOUBLE, MPI_SUM, 0, (MPI_Comm)communicator );
CHECK_MPI( rval, err );
if( rank == 0 )
{
*freeElementCount = (size_t)d_sum_recv[0];
*invertedElementCount = (int)d_sum_recv[1];
*elementCount = (size_t)d_sum_recv[2];
*invertedSampleCount = (int)d_sum_recv[3];
*sampleCount = (size_t)d_sum_recv[4];
*count = (long unsigned int)d_sum_recv[5];
*invalid = (long unsigned int)d_sum_recv[6];
*sum = d_sum_recv[7];
*sqrSum = d_sum_recv[8];
}
}
| void MBMesquite::ParallelHelperImpl::compute_first_independent_set | ( | std::vector< Mesh::VertexHandle > & | fixed_vertices | ) | [protected, virtual] |
Implements MBMesquite::ParallelHelper.
Definition at line 977 of file ParallelHelper.cpp.
References communication_model, compute_independent_set(), in_independent_set, iteration, neighbourProc, neighbourProcRecv, neighbourProcRecvRemain, neighbourProcSend, neighbourProcSendRemain, nprocs, num_already_smoothed_vertices, num_vtx_partition_boundary, num_vtx_partition_boundary_local, part_smoothed_flag, part_vertices, rank, and unghost_vertices.
{
if( nprocs == 1 ) return;
int i;
// to avoid all reduce we need to know how many vertices we send & receive
if( communication_model & 1 ) // AVOID_ALL_REDUCE
{
for( i = 0; i < (long)neighbourProc.size(); i++ )
{
neighbourProcSendRemain[i] = neighbourProcSend[i];
neighbourProcRecvRemain[i] = neighbourProcRecv[i];
}
}
// this is iteration zero of the bounday smooting process
iteration = 0;
// mark all boundary partition vertices as not smoothed
for( i = 0; i < num_vtx_partition_boundary; i++ )
{
part_smoothed_flag[i] = 0;
}
// populates the in_independent_set and the vertex export arrays
compute_independent_set();
// counts how many vertices are already smoothed
num_already_smoothed_vertices = 0;
fixed_vertices.clear();
/* mark which local boundary partition vertices are already smoothed (i.e. they are in the 1st
* independent set) */
for( i = 0; i < num_vtx_partition_boundary_local; i++ )
{
if( in_independent_set[i] )
{
part_smoothed_flag[i] = 1;
num_already_smoothed_vertices++;
}
else
{
fixed_vertices.push_back( part_vertices[i] ); // fix vertices *not* in the independent set
}
}
if( false )
{
printf( "[%d]i%d after first we smoothed %d of %d\n", rank, iteration, num_already_smoothed_vertices,
num_vtx_partition_boundary_local );
fflush( NULL );
}
// fix the ghost vertices that are smoothed on another processor
for( i = num_vtx_partition_boundary_local; i < num_vtx_partition_boundary; i++ )
{
fixed_vertices.push_back( part_vertices[i] );
}
// fix the ghost vertices that are unused
for( i = 0; i < (int)( unghost_vertices.size() ); i++ )
{
fixed_vertices.push_back( unghost_vertices[i] );
}
}
| void MBMesquite::ParallelHelperImpl::compute_independent_set | ( | ) | [private] |
Definition at line 2693 of file ParallelHelper.cpp.
References exportProc, exportVtxGIDs, exportVtxLIDs, in_independent_set, iteration, l, num_exportVtx, num_vtx_partition_boundary, num_vtx_partition_boundary_local, part_gid, part_proc_owner, part_rand_number, part_smoothed_flag, rank, size, and vtx_off_proc_list.
Referenced by compute_first_independent_set(), and compute_next_independent_set().
{
int i, j, k, l;
int incident_vtx;
bool done;
for( i = 0; i < num_vtx_partition_boundary_local; i++ )
in_independent_set[i] = false;
bool found_more = true;
int found_iter = 0;
num_exportVtx = 0;
while( found_more )
{
found_iter++;
found_more = false;
for( i = 0; i < num_vtx_partition_boundary_local; i++ )
{
/* if this vertex could become part of the independent set */
if( part_smoothed_flag[i] == 0 && in_independent_set[i] == false )
{
/* assume it's in the independent set */
done = false;
/* then loop over the neighbors it has on other processors */
for( j = 0; !done && j < (long)vtx_off_proc_list[i].size(); j++ )
{
incident_vtx = vtx_off_proc_list[i][j];
/* if this neighbour has not yet been smoothed and is not covered and ... */
if( part_smoothed_flag[incident_vtx] == 0 )
{
/* ... has a higher rand_number than me */
if( part_rand_number[i] < part_rand_number[incident_vtx] )
{
/* then I am not in the independent set */
done = true;
break;
}
/* ... or has the same rand_number than me but a higher processor id */
else if( ( part_rand_number[i] == part_rand_number[incident_vtx] ) &&
( rank < part_proc_owner[incident_vtx] ) )
{
/* then I am not in the independent set */
done = true;
break;
}
}
}
/* if the vertex is in the independent set, add it to the export list */
if( !done )
{
found_more = true;
// if (found_iter > 1) printf("[%d]i%d found another one %d in iteration
//%d\n",rank,iteration,i, found_iter);
in_independent_set[i] = true;
/* mark vertices with lower random numbers as covered */
for( j = 0; j < (long)vtx_off_proc_list[i].size(); j++ )
{
incident_vtx = vtx_off_proc_list[i][j];
/* if this neighbour has not yet been smoothed or covered mark it as covered
*/
if( part_smoothed_flag[incident_vtx] == 0 )
{
part_smoothed_flag[incident_vtx] = 2;
}
}
k = num_exportVtx;
/* then loop over the neighbors it has on other processors */
for( j = 0; j < (long)vtx_off_proc_list[i].size(); j++ )
{
incident_vtx = vtx_off_proc_list[i][j];
/* check to see if this processor already on the list */
done = false;
for( l = k; l < num_exportVtx && !done; l++ )
{
if( exportProc[l] == part_proc_owner[incident_vtx] )
{
done = true;
}
}
/* if it's not on the list add it */
if( !done )
{
exportVtxLIDs[num_exportVtx] = i;
exportVtxGIDs[num_exportVtx] = part_gid[i];
exportProc[num_exportVtx] = part_proc_owner[incident_vtx];
num_exportVtx++;
}
}
}
}
}
}
if( false )
{
int in_set = 0;
for( i = 0; i < num_vtx_partition_boundary_local; i++ )
if( in_independent_set[i] ) in_set++;
;
printf( "[%d]i%d independent set has %d of %d vertices sent out %d times\n", rank, iteration, in_set,
num_vtx_partition_boundary_local, num_exportVtx );
fflush( NULL );
}
/* unmark the vertices that have been marked as covered */
for( i = num_vtx_partition_boundary_local; i < num_vtx_partition_boundary; i++ )
if( part_smoothed_flag[i] == 2 ) part_smoothed_flag[i] = 0;
}
| bool MBMesquite::ParallelHelperImpl::compute_next_independent_set | ( | ) | [protected, virtual] |
Implements MBMesquite::ParallelHelper.
Definition at line 1073 of file ParallelHelper.cpp.
References compute_independent_set(), global_work_remains, iteration, next_vtx_partition_boundary, nprocs, and rank.
{
if( nprocs == 1 ) return false;
if( global_work_remains && ( iteration < 20 ) )
{
iteration++;
if( false ) printf( "[%d] work remains %d after %d iterations\n", rank, global_work_remains, iteration );
compute_independent_set();
next_vtx_partition_boundary = 0;
return true;
}
else
{
if( global_work_remains )
{
printf( "WARNING: global work remains %d after %d iterations\n", global_work_remains, iteration );
}
return false;
}
}
| bool MBMesquite::ParallelHelperImpl::get_next_partition_boundary_vertex | ( | MBMesquite::Mesh::VertexHandle & | vertex_handle | ) | [protected, virtual] |
Implements MBMesquite::ParallelHelper.
Definition at line 1095 of file ParallelHelper.cpp.
References in_independent_set, iteration, next_vtx_partition_boundary, num_already_smoothed_vertices, num_vtx_partition_boundary_local, part_smoothed_flag, part_vertices, and rank.
{
while( next_vtx_partition_boundary < num_vtx_partition_boundary_local )
{
if( in_independent_set[next_vtx_partition_boundary] )
{
vertex_handle = part_vertices[next_vtx_partition_boundary];
num_already_smoothed_vertices++;
assert( part_smoothed_flag[next_vtx_partition_boundary] == 0 );
part_smoothed_flag[next_vtx_partition_boundary] = 1;
next_vtx_partition_boundary++;
return true;
}
next_vtx_partition_boundary++;
}
if( false )
{
printf( "[%d]i%d after next we smoothed %d of %d\n", rank, iteration, num_already_smoothed_vertices,
num_vtx_partition_boundary_local );
fflush( NULL );
}
return false;
}
| int MBMesquite::ParallelHelperImpl::get_nprocs | ( | ) | const [protected, virtual] |
Implements MBMesquite::ParallelHelper.
Definition at line 2809 of file ParallelHelper.cpp.
References nprocs.
{
return nprocs;
}
| int MBMesquite::ParallelHelperImpl::get_rank | ( | ) | const [protected, virtual] |
Implements MBMesquite::ParallelHelper.
Definition at line 2804 of file ParallelHelper.cpp.
References rank.
{
return rank;
}
| bool MBMesquite::ParallelHelperImpl::is_our_element | ( | Mesh::ElementHandle | element_handle, |
| MsqError & | err | ||
| ) | const [protected, virtual] |
Implements MBMesquite::ParallelHelper.
Definition at line 2814 of file ParallelHelper.cpp.
References ARRPTR, MBMesquite::Mesh::elements_get_attached_vertices(), mesh, MSQ_ERRZERO, rank, and MBMesquite::ParallelMesh::vertices_get_processor_id().
{
int i;
std::vector< Mesh::VertexHandle > pvertices;
std::vector< size_t > junk;
mesh->elements_get_attached_vertices( &element_handle, 1, pvertices, junk, err );
MSQ_ERRZERO( err );
int num_verts = pvertices.size();
std::vector< int > proc_ids( num_verts );
mesh->vertices_get_processor_id( ARRPTR( pvertices ), ARRPTR( proc_ids ), num_verts, err );
MSQ_ERRZERO( err );
int max_proc_id = proc_ids[0];
for( i = 1; i < num_verts; i++ )
if( max_proc_id < proc_ids[i] ) max_proc_id = proc_ids[i];
return ( max_proc_id == rank );
}
| bool MBMesquite::ParallelHelperImpl::is_our_vertex | ( | Mesh::VertexHandle | vertex_handle, |
| MsqError & | err | ||
| ) | const [protected, virtual] |
Implements MBMesquite::ParallelHelper.
Definition at line 2831 of file ParallelHelper.cpp.
References mesh, MSQ_CHKERR, rank, and MBMesquite::ParallelMesh::vertices_get_processor_id().
{
int proc_id;
mesh->vertices_get_processor_id( &vertex_handle, &proc_id, 1, err );
return !MSQ_CHKERR( err ) && ( proc_id == rank );
}
| void MBMesquite::ParallelHelperImpl::set_communication_model | ( | int | model, |
| MsqError & | err | ||
| ) | [virtual] |
Implements MBMesquite::ParallelHelper.
Definition at line 351 of file ParallelHelper.cpp.
References communication_model.
{
communication_model = model;
}
| void MBMesquite::ParallelHelperImpl::set_communicator | ( | size_t | comm | ) | [virtual] |
Implements MBMesquite::ParallelHelper.
Definition at line 344 of file ParallelHelper.cpp.
References communicator, nprocs, and rank.
Referenced by main(), ParallelHelperImpl(), set_communicator(), and test().
{
communicator = comm;
MPI_Comm_rank( (MPI_Comm)communicator, &rank );
MPI_Comm_size( (MPI_Comm)communicator, &nprocs );
}
| void MBMesquite::ParallelHelperImpl::set_communicator | ( | const void * | comm | ) | [inline] |
Definition at line 88 of file ParallelHelper.hpp.
References set_communicator().
{
set_communicator( reinterpret_cast< size_t >( comm ) );
}
| void MBMesquite::ParallelHelperImpl::set_generate_random_numbers | ( | int | grn, |
| MsqError & | err | ||
| ) | [virtual] |
Implements MBMesquite::ParallelHelper.
Definition at line 356 of file ParallelHelper.cpp.
References generate_random_numbers.
{
this->generate_random_numbers = grn;
}
| void MBMesquite::ParallelHelperImpl::set_parallel_mesh | ( | ParallelMesh * | mesh | ) | [virtual] |
Implements MBMesquite::ParallelHelper.
Definition at line 339 of file ParallelHelper.cpp.
References mesh.
Referenced by main(), and test().
{
this->mesh = pmesh;
}
| void MBMesquite::ParallelHelperImpl::smoothing_close | ( | MsqError & | err | ) | [protected, virtual] |
Implements MBMesquite::ParallelHelper.
Definition at line 1170 of file ParallelHelper.cpp.
References ARRPTR, CHECK_MPI, communicator, GHOST_NODE_VERTEX_UPDATES, mesh, MBMesquite::MsqVertex::MSQ_CULLED, MSQ_ERRRTN, MBMesquite::MsqVertex::MSQ_HARD_FIXED, nprocs, num_vertex, rank, unghost_num_procs, unghost_num_vtx, unghost_procs, unghost_procs_num_vtx, unghost_procs_offset, unghost_vertices, update_gid, update_num_procs, update_num_vtx, update_procs, update_procs_num_vtx, update_procs_offset, MBMesquite::vertex_map_find(), MBMesquite::vertex_map_insert(), MBMesquite::Mesh::vertex_set_coordinates(), vertices, MBMesquite::Mesh::vertices_get_byte(), MBMesquite::Mesh::vertices_get_coordinates(), MBMesquite::ParallelMesh::vertices_get_global_id(), and MBMesquite::ParallelMesh::vertices_get_processor_id().
{
int i, j, rval;
if( nprocs == 1 ) return;
// printf("[%d] used %d iterations\n", rank, iteration);
// communicate unused ghost nodes
std::vector< double > update_updates;
std::vector< MPI_Request > update_requests;
if( update_num_procs )
{
/* get the tags so we can find the requested vertices */
std::vector< size_t > gid( num_vertex );
mesh->vertices_get_global_id( ARRPTR( vertices ), ARRPTR( gid ), num_vertex, err );MSQ_ERRRTN( err );
std::vector< unsigned char > app_fixed( num_vertex );
mesh->vertices_get_byte( ARRPTR( vertices ), ARRPTR( app_fixed ), num_vertex, err );MSQ_ERRRTN( err );
std::vector< int > proc_owner( num_vertex );
mesh->vertices_get_processor_id( ARRPTR( vertices ), ARRPTR( proc_owner ), num_vertex, err );MSQ_ERRRTN( err );
if( false )
{
int ncull = 0;
for( i = 0; i < num_vertex; ++i )
{
if( app_fixed[i] & MsqVertex::MSQ_CULLED )
{
++ncull;
}
}
std::cout << "P[" << rank << "] ncull= " << ncull << " num_vertex= " << num_vertex << std::endl;
}
/* only interested in fixed flag from vertex byte? Clear others. */
// srkenno AT sandia.gov 1/19/12: bug fix: changed from |= which makes all vertices fixed
for( i = 0; i < num_vertex; ++i )
app_fixed[i] &= MsqVertex::MSQ_HARD_FIXED;
/* insert all our unfixed vertices into a map so we can find the requested vertices
* efficiently */
VertexIdMap temp_vid_map;
for( j = 0; j < num_vertex; j++ )
{
if( proc_owner[j] == rank && app_fixed[j] == false )
{
vertex_map_insert( temp_vid_map, gid[j], rank, j );
}
}
/* deallocate the tags */
// delete [] gid; gid = 0;
// delete [] app_fixed; app_fixed = 0;
// delete [] proc_owner; proc_owner = 0;
/* find the requested updates and collect them into an array */
MBMesquite::MsqVertex coordinates;
update_updates.resize( update_num_vtx * 3 );
for( i = 0; i < update_num_vtx; i++ )
{
j = vertex_map_find( temp_vid_map, update_gid[i], rank );
mesh->vertices_get_coordinates( &( vertices[j] ), &coordinates, 1, err );MSQ_ERRRTN( err );
update_updates[3 * i + 0] = coordinates[0];
update_updates[3 * i + 1] = coordinates[1];
update_updates[3 * i + 2] = coordinates[2];
// printf("[%d] send gid %d with %g %g %g\n", rank, update_gid[i], coordinates[0],
// coordinates[1], coordinates[2]);
}
/* deallocate the map and the gid array */
// delete temp_vid_map; temp_vid_map = 0;
// delete [] update_gid; update_gid = 0;
update_requests.resize( update_num_procs );
/* send each processor the unused ghost node updates that they requested */
for( j = 0; j < update_num_procs; j++ )
{
rval = MPI_Isend( &( update_updates[update_procs_offset[j] * 3] ), update_procs_num_vtx[j] * 3, MPI_DOUBLE,
update_procs[j], GHOST_NODE_VERTEX_UPDATES, (MPI_Comm)communicator,
&( update_requests[j] ) );
// printf("[%d] sending %d of %d from %d with offset %d \n", rank,
// update_procs_num_vtx[j], update_num_vtx, update_procs[j],
// update_procs_offset[j]);
CHECK_MPI( rval, err );
}
/* deallocate more arrays that we no longer need */
// delete [] update_procs_offset; update_procs_offset = 0;
// delete [] update_procs_num_vtx; update_procs_num_vtx = 0;
// delete [] update_procs; update_procs = 0;
}
if( unghost_num_procs )
{
std::vector< MPI_Request > unghost_requests( unghost_num_procs );
/* receive from each processor the unused ghost nodes updates i want from them */
std::vector< double > unghost_updates( unghost_num_vtx * 3 );
for( j = 0; j < unghost_num_procs; j++ )
{
rval = MPI_Irecv( &( unghost_updates[unghost_procs_offset[j] * 3] ), unghost_procs_num_vtx[j] * 3,
MPI_DOUBLE, unghost_procs[j], GHOST_NODE_VERTEX_UPDATES, (MPI_Comm)communicator,
&( unghost_requests[j] ) );
// printf("[%d] receiving %d of %d from %d with offset %d \n", rank,
// unghost_procs_num_vtx[j], unghost_num_vtx, unghost_procs[j],
// unghost_procs_offset[j]);
CHECK_MPI( rval, err );
}
/* deallocate more arrays that we no longer need */
// delete [] unghost_procs_offset; unghost_procs_offset = 0;
// delete [] unghost_procs_num_vtx; unghost_procs_num_vtx = 0;
// delete [] unghost_procs; unghost_procs = 0;
std::vector< MPI_Status > status( unghost_num_procs );
rval = MPI_Waitall( unghost_num_procs, ARRPTR( unghost_requests ), ARRPTR( status ) );
CHECK_MPI( rval, err );
/* apply the received updates for the unused ghost vertices */
for( i = 0; i < unghost_num_vtx; i++ )
{
MBMesquite::Vector3D coordinates;
coordinates[0] = unghost_updates[3 * i + 0];
coordinates[1] = unghost_updates[3 * i + 1];
coordinates[2] = unghost_updates[3 * i + 2];
// printf("[%d] recv %g %g %g\n", rank, coordinates[0], coordinates[1],
// coordinates[2]);
mesh->vertex_set_coordinates( unghost_vertices[i], coordinates, err );MSQ_ERRRTN( err );
}
/* deallocate more arrays that we no longer need */
// delete unghost_vertices; unghost_vertices = 0;
// delete [] unghost_updates; unghost_updates = 0;
// delete [] unghost_requests; unghost_requests = 0;
}
// if (update_num_procs)
//{
// delete [] update_updates; update_updates = 0;
// delete [] update_requests; update_requests = 0;
//}
// if (vertices) delete vertices; vertices = 0;
// if (vtx_in_partition_boundary) delete [] vtx_in_partition_boundary; vtx_in_partition_boundary
// = 0; if (part_vertices) delete part_vertices; part_vertices = 0; if (unghost_vertices) delete
// unghost_vertices; unghost_vertices = 0; if (part_proc_owner) delete [] part_proc_owner;
// part_proc_owner = 0; if (part_gid) delete [] part_gid; part_gid = 0; if (part_smoothed_flag)
// delete [] part_smoothed_flag; part_smoothed_flag = 0; if (part_rand_number) delete []
// part_rand_number; part_rand_number = 0; if (exportVtxGIDs) delete [] exportVtxGIDs;
// exportVtxGIDs = 0; if (exportVtxLIDs) delete [] exportVtxLIDs; exportVtxLIDs = 0; if
// (exportProc) delete [] exportProc; exportProc = 0; if (in_independent_set) delete []
// in_independent_set; in_independent_set = 0; if (vid_map) delete vid_map; vid_map = 0; if
// (neighbourProcSend) delete [] neighbourProcSend; neighbourProcSend = 0; if (neighbourProcRecv)
// delete [] neighbourProcRecv; neighbourProcRecv = 0; if (neighbourProcSendRemain) delete []
// neighbourProcSendRemain; neighbourProcSendRemain = 0; if (neighbourProcRecvRemain) delete []
// neighbourProcRecvRemain; neighbourProcRecvRemain = 0; if (vtx_off_proc_list_size) delete []
// vtx_off_proc_list_size; vtx_off_proc_list_size = 0; if (vtx_off_proc_list) {
// for (i = 0; i < num_vtx_partition_boundary_local; i++) free(vtx_off_proc_list[i]);
// delete [] vtx_off_proc_list; vtx_off_proc_list = 0;
//}
// if (neighbourProc) free(neighbourProc); neighbourProc = 0;
}
| void MBMesquite::ParallelHelperImpl::smoothing_init | ( | MsqError & | err | ) | [protected, virtual] |
Implements MBMesquite::ParallelHelper.
Definition at line 361 of file ParallelHelper.cpp.
References ARRPTR, CHECK_MPI, communication_model, communicator, MBMesquite::Mesh::elements_get_attached_vertices(), exportProc, exportVtxGIDs, exportVtxLIDs, MBMesquite::generate_random_number(), generate_random_numbers, MBMesquite::Mesh::get_all_elements(), MBMesquite::Mesh::get_all_vertices(), GHOST_NODE_INFO, GHOST_NODE_VERTEX_GIDS, GHOST_NODE_VERTICES_WANTED, in_independent_set, MBMesquite::Mesh::INT, MBMesquite::MsqError::INVALID_STATE, iteration, l, mesh, MBMesquite::MsqVertex::MSQ_CULLED, MSQ_ERRRTN, MBMesquite::MsqVertex::MSQ_HARD_FIXED, MSQ_SETERR, MBMesquite::my_quicksort(), neighbourProc, neighbourProcRecv, neighbourProcRecvRemain, neighbourProcSend, neighbourProcSendRemain, nprocs, num_vertex, num_vtx_partition_boundary, num_vtx_partition_boundary_local, num_vtx_partition_boundary_remote, part_gid, part_proc_owner, part_rand_number, part_smoothed_flag, part_vertices, rank, size, MBMesquite::Mesh::tag_create(), MBMesquite::Mesh::tag_delete(), MBMesquite::Mesh::tag_get_vertex_data(), MBMesquite::Mesh::tag_set_vertex_data(), total_num_vertices_to_recv, total_num_vertices_to_smooth, unghost_num_procs, unghost_num_vtx, unghost_procs, unghost_procs_num_vtx, unghost_procs_offset, unghost_vertices, update_gid, update_num_procs, update_num_vtx, update_procs, update_procs_num_vtx, update_procs_offset, MBMesquite::vertex_map_insert(), vertices, MBMesquite::Mesh::vertices_get_attached_elements(), MBMesquite::Mesh::vertices_get_byte(), MBMesquite::ParallelMesh::vertices_get_global_id(), MBMesquite::ParallelMesh::vertices_get_processor_id(), vid_map, vtx_in_partition_boundary, and vtx_off_proc_list.
{
int i, j, k, rval;
size_t l;
if( !mesh )
{
MSQ_SETERR( err )( MsqError::INVALID_STATE );
return;
}
if( nprocs == 1 ) return;
/* get the vertices */
mesh->get_all_vertices( vertices, err );MSQ_ERRRTN( err );
num_vertex = vertices.size();
/* allocate the data arrays we'll use for smoothing */
std::vector< size_t > gid( num_vertex );
std::vector< int > proc_owner( num_vertex );
std::vector< unsigned char > app_fixed( num_vertex );
/* get the data from the mesquite mesh */
mesh->vertices_get_global_id( ARRPTR( vertices ), ARRPTR( gid ), num_vertex, err );MSQ_ERRRTN( err );
mesh->vertices_get_byte( ARRPTR( vertices ), ARRPTR( app_fixed ), num_vertex, err );MSQ_ERRRTN( err );
mesh->vertices_get_processor_id( ARRPTR( vertices ), ARRPTR( proc_owner ), num_vertex, err );MSQ_ERRRTN( err );
if( false )
{
int ncull = 0;
for( i = 0; i < num_vertex; ++i )
{
if( app_fixed[i] & MsqVertex::MSQ_CULLED )
{
++ncull;
}
}
std::cout << "P[" << rank << "] smoothing_init ncull= " << ncull << " num_vertex= " << num_vertex << std::endl;
}
/* only interested in fixed flag from vertex byte? Clear others. */
// srkenno AT sandia.gov 1/19/12: bug fix: changed from |= which makes all vertices fixed
for( i = 0; i < num_vertex; ++i )
app_fixed[i] &= MsqVertex::MSQ_HARD_FIXED;
/* create temporary Tag for the local IDs */
std::vector< int > lid( num_vertex );
for( i = 0; i < num_vertex; i++ )
lid[i] = i;
const char LOCAL_ID_NAME[] = "LOCAL_ID";
TagHandle lid_tag = mesh->tag_create( LOCAL_ID_NAME, Mesh::INT, 1, NULL, err );MSQ_ERRRTN( err );
mesh->tag_set_vertex_data( lid_tag, num_vertex, ARRPTR( vertices ), ARRPTR( lid ), err );MSQ_ERRRTN( err );
if( false ) printf( "[%d] set local tags on %d vertices\n", rank, num_vertex );
/* get the elements */
std::vector< MBMesquite::Mesh::ElementHandle > elements;
mesh->get_all_elements( elements, err );MSQ_ERRRTN( err );
int num_elems = elements.size();
/****************************************************************
PARTITION BOUNDARY VERTEX DETERMINATION
***********************************************************************/
/* initialize the vertex partition boundary array */
vtx_in_partition_boundary.clear();
vtx_in_partition_boundary.resize( num_vertex, 0 );
int incident_vtx, vtx_off_proc, vtx_on_proc;
/* get the array that contains the adjacent vertices for each mesh element */
std::vector< MBMesquite::Mesh::VertexHandle > adj_vertices;
std::vector< size_t > vtx_offsets;
mesh->elements_get_attached_vertices( ARRPTR( elements ), num_elems, adj_vertices, vtx_offsets, err );
std::vector< int > adj_vertices_lid( adj_vertices.size() );
mesh->tag_get_vertex_data( lid_tag, adj_vertices.size(), ARRPTR( adj_vertices ), ARRPTR( adj_vertices_lid ), err );
if( false ) printf( "[%d] gotten adjacent elements for %d elements\n", rank, num_elems );
/* determine which vertices are smoothed as part of the boundary (and which are unused ghost
* vertices) */
num_vtx_partition_boundary_local = 0;
num_vtx_partition_boundary_remote = 0;
for( i = 0; i < num_elems; i++ )
{
/* count how many vertices of the current element are on/off a different processor */
vtx_off_proc = 0;
vtx_on_proc = 0;
for( j = vtx_offsets[i]; j < (int)( vtx_offsets[i + 1] ); j++ )
{
incident_vtx = adj_vertices_lid[j];
/* obviously the vertex only counts if it is not app_fixed */
if( !app_fixed[incident_vtx] )
{
if( proc_owner[incident_vtx] != rank )
{
vtx_off_proc++;
}
else
{
vtx_on_proc++;
}
}
}
/* if vertices are on different processors mark all local vertices as boundary1 and all
* remote vertices as boundary2 */
if( vtx_off_proc > 0 && vtx_on_proc > 0 )
{
/* collect stats */
// smooth_stats.num_part_bndy_elem++;
/* mark the vertices */
for( j = vtx_offsets[i]; j < (int)( vtx_offsets[i + 1] ); j++ )
{
incident_vtx = adj_vertices_lid[j];
/* obviously the vertex does not need to be marked if it was already marked or if it
* is app_fixed*/
if( vtx_in_partition_boundary[incident_vtx] <= 0 && app_fixed[incident_vtx] == 0 )
{
/* mark and count the vertex */
if( proc_owner[incident_vtx] != rank )
{
vtx_in_partition_boundary[incident_vtx] = 2;
num_vtx_partition_boundary_remote++;
}
else
{
vtx_in_partition_boundary[incident_vtx] = 1;
num_vtx_partition_boundary_local++;
}
}
}
}
else if( vtx_off_proc > 0 )
{
/* mark the vertices as boundary-1 (aka unused ghost) if the element has only
* off-processor vertices */
for( j = vtx_offsets[i]; j < (int)( vtx_offsets[i + 1] ); j++ )
{
incident_vtx = adj_vertices_lid[j];
/* obviously the vertex is not marked if it was already marked or if it is
* app_fixed*/
if( vtx_in_partition_boundary[incident_vtx] == 0 && app_fixed[incident_vtx] == 0 )
{
vtx_in_partition_boundary[incident_vtx] = -1;
}
}
}
}
if( false )
{
printf( "[%d]i%d local %d remote %d ", rank, iteration, num_vtx_partition_boundary_local,
num_vtx_partition_boundary_remote );
printf( "[%d]i%d pb1 ", rank, iteration );
for( i = 0; i < num_vertex; i++ )
if( vtx_in_partition_boundary[i] == 1 ) printf( "%d,%lu ", i, gid[i] );
printf( "\n" );
printf( "[%d]i%d pb2 ", rank, iteration );
for( i = 0; i < num_vertex; i++ )
if( vtx_in_partition_boundary[i] == 2 ) printf( "%d,%lu ", i, gid[i] );
printf( "\n" );
fflush( NULL );
}
num_vtx_partition_boundary = num_vtx_partition_boundary_local + num_vtx_partition_boundary_remote;
/********************************************************************
COLLECT THE PARTITION BOUNDARY VERTICES AND THE UNUSED GHOST VERTICES
********************************************************************/
/* create the vectors to store the partition boundary vertex data */
part_vertices.resize( num_vtx_partition_boundary );
part_proc_owner.resize( num_vtx_partition_boundary );
part_gid.resize( num_vtx_partition_boundary );
part_smoothed_flag.resize( num_vtx_partition_boundary );
part_rand_number.resize( num_vtx_partition_boundary );
/* create the partition boundary map and its inverse */
std::vector< int > vtx_partition_boundary_map_inverse( num_vertex );
j = 0;
/* first we map the partition boundary vertices that we will smooth on this processor */
for( i = 0; i < num_vertex; i++ )
{
if( vtx_in_partition_boundary[i] == 1 )
{
part_vertices[j] = vertices[i];
part_proc_owner[j] = rank;
assert( proc_owner[i] == rank );
part_gid[j] = gid[i];
vtx_partition_boundary_map_inverse[i] = j;
j++;
}
}
vid_map.clear();
/* then we map the ghost vertices that will be smoothed on other processors */
for( i = 0; i < num_vertex; i++ )
{
if( vtx_in_partition_boundary[i] == 2 )
{
part_vertices[j] = vertices[i];
part_proc_owner[j] = proc_owner[i];
assert( proc_owner[i] != rank );
part_gid[j] = gid[i];
vtx_partition_boundary_map_inverse[i] = j;
/* only insert those vertices in the map that are smoothed on other processors */
vertex_map_insert( vid_map, part_gid[j], part_proc_owner[j], j );
// printf("[%d] inserting vertex with gid %u and pid %d \n", rank, part_gid[j],
// part_proc_owner[j]);
j++;
}
}
/* create our own 'very pseudo random' numbers */
for( i = 0; i < num_vtx_partition_boundary; i++ )
part_rand_number[i] = generate_random_number( generate_random_numbers, part_proc_owner[i], part_gid[i] );
/* count the number of unused ghost vertices */
unghost_num_vtx = 0;
for( i = 0; i < num_vertex; i++ )
{
if( vtx_in_partition_boundary[i] == -1 )
{
unghost_num_vtx++;
}
}
// printf("[%d] found %d unused ghost vertices (local %d remote %d)\n",rank, unghost_num_vtx,
// num_vtx_partition_boundary_local,num_vtx_partition_boundary_remote);
/* create the vectors to store the unused ghost vertices */
unghost_vertices.resize( unghost_num_vtx );
std::vector< int > unghost_proc_owner( unghost_num_vtx );
std::vector< size_t > unghost_gid( unghost_num_vtx );
/* store the unused ghost vertices that are copies of vertices from other processors and will
* need to be received */
j = 0;
for( i = 0; i < num_vertex; i++ )
{
if( vtx_in_partition_boundary[i] == -1 )
{
unghost_vertices[j] = vertices[i];
unghost_proc_owner[j] = proc_owner[i];
assert( proc_owner[i] != rank );
unghost_gid[j] = gid[i];
// printf(" %d", unghost_gid[j]);
j++;
}
}
/* no longer needed */
// delete [] gid; gid = 0;
// delete [] proc_owner; proc_owner = 0;
unghost_num_procs = 0;
unghost_procs.clear();
unghost_procs_offset.clear();
unghost_procs_num_vtx.clear();
if( unghost_num_vtx )
{
/* sort the unused ghost vertices by processor */
my_quicksort( ARRPTR( unghost_proc_owner ), ARRPTR( unghost_gid ), &( unghost_vertices[0] ), 0,
unghost_num_vtx - 1 );
/* count the number of processors we have unused ghost data from that we want to get updated
*/
unghost_num_procs = 1;
for( i = 1; i < unghost_num_vtx; i++ )
{
if( unghost_proc_owner[i - 1] != unghost_proc_owner[i] ) unghost_num_procs++;
}
/* get the ids of those processors and the number of vertices we want from each */
unghost_procs.resize( unghost_num_procs );
unghost_procs_offset.resize( unghost_num_procs + 1 );
unghost_procs_num_vtx.resize( unghost_num_procs );
unghost_procs[0] = unghost_proc_owner[0];
unghost_procs_offset[0] = 0;
for( i = 1, j = 1; i < unghost_num_vtx; i++ )
{
if( unghost_proc_owner[i - 1] != unghost_proc_owner[i] )
{
unghost_procs[j] = unghost_proc_owner[i];
unghost_procs_offset[j] = i;
unghost_procs_num_vtx[j - 1] = unghost_procs_offset[j] - unghost_procs_offset[j - 1];
assert( unghost_procs_num_vtx[j - 1] > 0 );
j++;
}
}
unghost_procs_offset[j] = i;
unghost_procs_num_vtx[j - 1] = unghost_procs_offset[j] - unghost_procs_offset[j - 1];
assert( unghost_procs_num_vtx[j - 1] > 0 );
assert( j == unghost_num_procs );
// delete [] unghost_proc_owner; unghost_proc_owner = 0;
// printf("[%d] have ugns from %d processor(s) (%d,%d,%d)\n", rank, unghost_num_procs,
// unghost_procs[0], (unghost_num_procs>1) ? unghost_procs[1] : -1, (unghost_num_procs>2) ?
// unghost_procs[1] : -1);
}
/* this will eventually store to how many processors each processor needs to send unused ghost
* data to */
std::vector< int > num_sends_of_unghost;
/* gather the information about how many processors need ghost data */
if( rank == 0 )
{
/* this will eventually store to how many processors each processor needs to send unused
* ghost data to */
num_sends_of_unghost.resize( nprocs );
}
/* temporary used for the initial gather in which each proc tells the root from how many procs
* it wants unused ghost data updates */
rval = MPI_Gather( &unghost_num_procs, 1, MPI_INT, ARRPTR( num_sends_of_unghost ), 1, MPI_INT, 0,
(MPI_Comm)communicator );
CHECK_MPI( rval, err );
/* now each processor tells the root node from which processors they want unused ghost nodes
* information */
if( rank == 0 )
{
int procs_num = 0;
int procs_max = 0;
/* first count how many processors will send unused ghost node info and find the maximum
* they will send */
for( i = 1; i < nprocs; i++ )
{
if( num_sends_of_unghost[i] )
{
procs_num++;
if( num_sends_of_unghost[i] > procs_max ) procs_max = num_sends_of_unghost[i];
}
}
/* clean the temporary used array */
for( i = 0; i < nprocs; i++ )
num_sends_of_unghost[i] = 0;
/* process rank 0's unused ghost nodes procs first */
for( j = 0; j < unghost_num_procs; j++ )
{
num_sends_of_unghost[unghost_procs[j]]++;
}
/* now we process messages from all other processors that want unused ghost node information
*/
int* unghost_procs_array = new int[procs_max];
for( i = 0; i < procs_num; i++ )
{
MPI_Status status;
rval = MPI_Recv( unghost_procs_array, procs_max, MPI_INT, MPI_ANY_SOURCE, GHOST_NODE_INFO,
(MPI_Comm)communicator, &status );
CHECK_MPI( rval, err );
int count;
MPI_Get_count( &status, MPI_INT, &count );
for( j = 0; j < count; j++ )
{
num_sends_of_unghost[unghost_procs_array[j]]++;
}
}
delete[] unghost_procs_array;
}
else
{
if( unghost_num_vtx )
{
rval = MPI_Send( ARRPTR( unghost_procs ), unghost_num_procs, MPI_INT, 0, GHOST_NODE_INFO,
(MPI_Comm)communicator );
CHECK_MPI( rval, err );
}
}
/* now the root node knows for each processor on how many other processors they have ghost nodes
* (which need updating) */
/* the scatter distributes this information to each processor */
rval = MPI_Scatter( ARRPTR( num_sends_of_unghost ), 1, MPI_INT, &update_num_procs, 1, MPI_INT, 0,
(MPI_Comm)communicator );
CHECK_MPI( rval, err );
// if (rank == 0) delete [] num_sends_of_unghost;
// printf("[%d] i have unused ghost nodes from %d procs and i need to send updates to %d
// procs\n", rank, unghost_num_procs, update_num_procs);
/* now the processors can negotiate amongst themselves: */
/* first tell each processor the number of unused ghost nodes we want from them */
std::vector< MPI_Request > requests_unghost( unghost_num_procs );
for( j = 0; j < unghost_num_procs; j++ )
{
rval = MPI_Isend( &( unghost_procs_num_vtx[j] ), 1, MPI_INT, unghost_procs[j], GHOST_NODE_VERTICES_WANTED,
(MPI_Comm)communicator, &( requests_unghost[j] ) );
CHECK_MPI( rval, err );
}
/* then listen to as many processors as there are that want updates from us */
std::vector< MPI_Request > requests_updates( update_num_procs );
update_procs_num_vtx.resize( update_num_procs );
for( j = 0; j < update_num_procs; j++ )
{
rval = MPI_Irecv( &( update_procs_num_vtx[j] ), 1, MPI_INT, MPI_ANY_SOURCE, GHOST_NODE_VERTICES_WANTED,
(MPI_Comm)communicator, &( requests_updates[j] ) );
CHECK_MPI( rval, err );
}
/* wait until we have heard from all processors how many ghost nodes updates they want from us
*/
std::vector< MPI_Status > status_update( update_num_procs );
update_procs.resize( update_num_procs );
rval = MPI_Waitall( update_num_procs, ARRPTR( requests_updates ), ARRPTR( status_update ) );
CHECK_MPI( rval, err );
for( j = 0; j < update_num_procs; j++ )
{
update_procs[j] = status_update[j].MPI_SOURCE;
// printf("[%d] i have to send %d vertices to processor %d\n", rank,
// update_procs_num_vtx[j], update_procs[j]);
}
/* count the total number of vertices that we need to update elsewhere */
update_procs_offset.resize( update_num_procs + 1 );
update_num_vtx = 0;
update_procs_offset[0] = 0;
for( j = 0; j < update_num_procs; j++ )
{
update_num_vtx += update_procs_num_vtx[j];
update_procs_offset[j + 1] = update_num_vtx;
}
/* create enough space to receive all the vertex indices */
update_gid.resize( update_num_vtx );
/* tell each processor which vertices we want from them */
for( j = 0; j < unghost_num_procs; j++ )
{
rval = MPI_Isend( &( unghost_gid[unghost_procs_offset[j]] ), unghost_procs_num_vtx[j],
sizeof( size_t ) == 4 ? MPI_INT : MPI_DOUBLE, unghost_procs[j], GHOST_NODE_VERTEX_GIDS,
(MPI_Comm)communicator, &( requests_unghost[j] ) );
CHECK_MPI( rval, err );
}
/* receive from each processor the info which vertices they want from us */
for( j = 0; j < update_num_procs; j++ )
{
rval = MPI_Irecv( &( update_gid[update_procs_offset[j]] ), update_procs_num_vtx[j],
sizeof( size_t ) == 4 ? MPI_INT : MPI_DOUBLE, update_procs[j], GHOST_NODE_VERTEX_GIDS,
(MPI_Comm)communicator, &( requests_updates[j] ) );
CHECK_MPI( rval, err );
}
/* wait until we have heard from all processors which vertices they want from us */
rval = MPI_Waitall( update_num_procs, ARRPTR( requests_updates ), ARRPTR( status_update ) );
CHECK_MPI( rval, err );
/* wait until we have sent to all processors which vertices we want from them */
std::vector< MPI_Status > status_unghost( unghost_num_procs );
rval = MPI_Waitall( unghost_num_procs, ARRPTR( requests_unghost ), ARRPTR( status_unghost ) );
CHECK_MPI( rval, err );
/*
for (j = 0; j < update_num_procs; j++)
{
printf("[%d] will send to proc %d:", rank, update_procs[j]);
for (i = update_procs_offset[j]; i < update_procs_offset[j+1]; i++) printf(" %d",
update_gid[i]); printf("\n");
}
*/
/***********************************************************************
COMPUTE THE SET OF NEIGHBORS THAT OUR VERTICES HAVE ON OTHER PROCESSORS
COMPUTE THE SET OF NEIGHBORS PROCESSORS
***********************************************************************/
if( num_vtx_partition_boundary_local == 0 )
{
/* this processor does not partake in the boundary smoothing */
neighbourProc.clear();
mesh->tag_delete( lid_tag, err );
vtx_partition_boundary_map_inverse.clear();
return;
}
/* init the neighbour processor list */
neighbourProc.clear();
/* init the neighbour lists */
vtx_off_proc_list.clear();
vtx_off_proc_list.resize( num_vtx_partition_boundary_local );
/* get the adjacency arrays that we need */
std::vector< MBMesquite::Mesh::ElementHandle > adj_elements;
std::vector< MBMesquite::Mesh::VertexHandle > adj_adj_vertices;
std::vector< size_t > elem_offsets;
std::vector< size_t > adj_vtx_offsets;
mesh->vertices_get_attached_elements( ARRPTR( part_vertices ), num_vtx_partition_boundary_local, adj_elements,
elem_offsets, err );
mesh->elements_get_attached_vertices( ARRPTR( adj_elements ), adj_elements.size(), adj_adj_vertices,
adj_vtx_offsets, err );
// delete adj_elements; adj_elements = 0;
std::vector< int > adj_adj_vertices_lid( adj_adj_vertices.size() );
mesh->tag_get_vertex_data( lid_tag, adj_adj_vertices.size(), ARRPTR( adj_adj_vertices ),
ARRPTR( adj_adj_vertices_lid ), err );
// delete adj_adj_vertices; adj_adj_vertices = 0;
mesh->tag_delete( lid_tag, err );
for( i = 0; i < num_vtx_partition_boundary_local; i++ )
{
/* loop over the elements surrounding that vertex */
for( j = elem_offsets[i]; j < (int)( elem_offsets[i + 1] ); j++ )
{
/* loop over the neighbors of the considered vertex (i.e. the vertices of these element)
*/
for( k = adj_vtx_offsets[j]; k < (int)( adj_vtx_offsets[j + 1] ); k++ )
{
/* get the next neighbour */
incident_vtx = adj_adj_vertices_lid[k];
/* if this neighbour is a vertex that is smoothed on a different processor */
if( vtx_in_partition_boundary[incident_vtx] == 2 )
{
/* then map it into our domain */
incident_vtx = vtx_partition_boundary_map_inverse[incident_vtx];
/* is this vertex already in our neighbour list ? */
if( std::find( vtx_off_proc_list[i].begin(), vtx_off_proc_list[i].end(), incident_vtx ) ==
vtx_off_proc_list[i].end() )
{
/* if the vertex is not in the list yet ... add it */
vtx_off_proc_list[i].push_back( incident_vtx );
/* is the processor of this vertex already in the processor list */
incident_vtx = part_proc_owner[incident_vtx];
/* check by scanning the list for this processor */
if( std::find( neighbourProc.begin(), neighbourProc.end(), incident_vtx ) ==
neighbourProc.end() )
{
/* the processor is not in the list yet ... add it */
neighbourProc.push_back( incident_vtx );
}
}
}
}
}
}
/* sort the list of neighbour processors */
std::sort( neighbourProc.begin(), neighbourProc.end() );
/***********************************************************************
COMPUTE HOW MANY VERTICES WE NEED TO SEND/RECV FROM EACH PROCESSOR
***********************************************************************/
neighbourProcSend.clear();
neighbourProcRecv.clear();
neighbourProcSendRemain.clear();
neighbourProcRecvRemain.clear();
if( communication_model & 1 ) // AVOID_ALL_REDUCE
{
total_num_vertices_to_smooth = num_vtx_partition_boundary_local;
total_num_vertices_to_recv = num_vtx_partition_boundary_remote;
neighbourProcSend.resize( neighbourProc.size(), 0 );
neighbourProcRecv.resize( neighbourProc.size(), 0 );
/* for each vertex we smooth find the processors we need to send it too */
for( i = 0; i < num_vtx_partition_boundary_local; i++ )
{
/* loop over its adjacent off-processor vertices */
for( j = 0; j < (long)vtx_off_proc_list[i].size(); j++ )
{
/* get the processor id of these vertices */
incident_vtx = part_proc_owner[vtx_off_proc_list[i][j]];
/* check if we got this processor id before */
for( k = 0; k < j; k++ )
{
if( incident_vtx == part_proc_owner[vtx_off_proc_list[i][k]] )
{
/* if we have has this procesor id already we do not need to count it again
*/
incident_vtx = -1;
break;
}
}
/* if this was a new processor id */
if( incident_vtx != -1 )
{
/* find the processor in the list and increment its counter */
for( l = 0; l < neighbourProc.size(); l++ )
{
if( neighbourProc[l] == incident_vtx )
{
neighbourProcSend[l]++;
break;
}
}
}
}
}
for( i = num_vtx_partition_boundary_local; i < num_vtx_partition_boundary; i++ )
{
incident_vtx = part_proc_owner[i];
for( l = 0; l < neighbourProc.size(); l++ )
{
if( neighbourProc[l] == incident_vtx )
{
neighbourProcRecv[l]++;
break;
}
}
}
neighbourProcSendRemain.resize( neighbourProc.size() );
neighbourProcRecvRemain.resize( neighbourProc.size() );
}
exportVtxGIDs.resize( num_vtx_partition_boundary );
exportVtxLIDs.resize( num_vtx_partition_boundary );
exportProc.resize( num_vtx_partition_boundary );
in_independent_set.resize( num_vtx_partition_boundary_local );
}
friend class QualityAssessor [friend] |
Reimplemented from MBMesquite::ParallelHelper.
Definition at line 107 of file ParallelHelper.hpp.
friend class VertexMover [friend] |
Reimplemented from MBMesquite::ParallelHelper.
Definition at line 96 of file ParallelHelper.hpp.
int MBMesquite::ParallelHelperImpl::communication_model [private] |
Definition at line 134 of file ParallelHelper.hpp.
Referenced by communicate_first_independent_set(), communicate_next_independent_set(), compute_first_independent_set(), ParallelHelperImpl(), set_communication_model(), and smoothing_init().
size_t MBMesquite::ParallelHelperImpl::communicator [private] |
Definition at line 133 of file ParallelHelper.hpp.
Referenced by comm_smoothed_vtx_b(), comm_smoothed_vtx_b_no_all(), comm_smoothed_vtx_nb(), comm_smoothed_vtx_nb_no_all(), comm_smoothed_vtx_tnb(), comm_smoothed_vtx_tnb_no_all(), communicate_all_true(), communicate_any_true(), communicate_histogram_to_zero(), communicate_min_max_to_all(), communicate_min_max_to_zero(), communicate_next_independent_set(), communicate_power_sum_to_zero(), communicate_sums_to_zero(), ParallelHelperImpl(), set_communicator(), smoothing_close(), and smoothing_init().
std::vector< int > MBMesquite::ParallelHelperImpl::exportProc [private] |
Definition at line 155 of file ParallelHelper.hpp.
Referenced by comm_smoothed_vtx_b(), comm_smoothed_vtx_b_no_all(), comm_smoothed_vtx_nb(), comm_smoothed_vtx_nb_no_all(), comm_smoothed_vtx_tnb(), comm_smoothed_vtx_tnb_no_all(), compute_independent_set(), ParallelHelperImpl(), and smoothing_init().
std::vector< size_t > MBMesquite::ParallelHelperImpl::exportVtxGIDs [private] |
Definition at line 153 of file ParallelHelper.hpp.
Referenced by comm_smoothed_vtx_b(), comm_smoothed_vtx_b_no_all(), comm_smoothed_vtx_nb(), comm_smoothed_vtx_nb_no_all(), comm_smoothed_vtx_tnb(), comm_smoothed_vtx_tnb_no_all(), compute_independent_set(), ParallelHelperImpl(), and smoothing_init().
std::vector< int > MBMesquite::ParallelHelperImpl::exportVtxLIDs [private] |
Definition at line 154 of file ParallelHelper.hpp.
Referenced by comm_smoothed_vtx_b(), comm_smoothed_vtx_b_no_all(), comm_smoothed_vtx_nb(), comm_smoothed_vtx_nb_no_all(), comm_smoothed_vtx_tnb(), comm_smoothed_vtx_tnb_no_all(), compute_independent_set(), ParallelHelperImpl(), and smoothing_init().
int MBMesquite::ParallelHelperImpl::generate_random_numbers [private] |
Definition at line 140 of file ParallelHelper.hpp.
Referenced by ParallelHelperImpl(), set_generate_random_numbers(), and smoothing_init().
int MBMesquite::ParallelHelperImpl::global_work_remains [private] |
Definition at line 169 of file ParallelHelper.hpp.
Referenced by communicate_first_independent_set(), communicate_next_independent_set(), and compute_next_independent_set().
std::vector< bool > MBMesquite::ParallelHelperImpl::in_independent_set [private] |
Definition at line 156 of file ParallelHelper.hpp.
Referenced by compute_first_independent_set(), compute_independent_set(), get_next_partition_boundary_vertex(), ParallelHelperImpl(), and smoothing_init().
int MBMesquite::ParallelHelperImpl::iteration [private] |
Definition at line 168 of file ParallelHelper.hpp.
Referenced by comm_smoothed_vtx_b(), comm_smoothed_vtx_b_no_all(), comm_smoothed_vtx_nb(), comm_smoothed_vtx_nb_no_all(), comm_smoothed_vtx_tnb(), comm_smoothed_vtx_tnb_no_all(), communicate_next_independent_set(), compute_first_independent_set(), compute_independent_set(), compute_next_independent_set(), get_next_partition_boundary_vertex(), and smoothing_init().
ParallelMesh* MBMesquite::ParallelHelperImpl::mesh [private] |
Definition at line 131 of file ParallelHelper.hpp.
Referenced by comm_smoothed_vtx_b(), comm_smoothed_vtx_b_no_all(), comm_smoothed_vtx_nb(), comm_smoothed_vtx_nb_no_all(), comm_smoothed_vtx_tnb(), comm_smoothed_vtx_tnb_no_all(), is_our_element(), is_our_vertex(), ParallelHelperImpl(), set_parallel_mesh(), smoothing_close(), and smoothing_init().
std::vector< int > MBMesquite::ParallelHelperImpl::neighbourProc [private] |
Definition at line 167 of file ParallelHelper.hpp.
Referenced by comm_smoothed_vtx_b(), comm_smoothed_vtx_b_no_all(), comm_smoothed_vtx_nb(), comm_smoothed_vtx_nb_no_all(), comm_smoothed_vtx_tnb(), comm_smoothed_vtx_tnb_no_all(), communicate_first_independent_set(), compute_first_independent_set(), ParallelHelperImpl(), and smoothing_init().
std::vector< int > MBMesquite::ParallelHelperImpl::neighbourProcRecv [private] |
Definition at line 161 of file ParallelHelper.hpp.
Referenced by comm_smoothed_vtx_nb(), comm_smoothed_vtx_nb_no_all(), compute_first_independent_set(), ParallelHelperImpl(), and smoothing_init().
std::vector< int > MBMesquite::ParallelHelperImpl::neighbourProcRecvRemain [private] |
Definition at line 163 of file ParallelHelper.hpp.
Referenced by comm_smoothed_vtx_b_no_all(), comm_smoothed_vtx_nb_no_all(), comm_smoothed_vtx_tnb_no_all(), compute_first_independent_set(), ParallelHelperImpl(), and smoothing_init().
std::vector< int > MBMesquite::ParallelHelperImpl::neighbourProcSend [private] |
Definition at line 160 of file ParallelHelper.hpp.
Referenced by compute_first_independent_set(), ParallelHelperImpl(), and smoothing_init().
std::vector< int > MBMesquite::ParallelHelperImpl::neighbourProcSendRemain [private] |
Definition at line 162 of file ParallelHelper.hpp.
Referenced by comm_smoothed_vtx_b_no_all(), comm_smoothed_vtx_nb_no_all(), comm_smoothed_vtx_tnb_no_all(), compute_first_independent_set(), ParallelHelperImpl(), and smoothing_init().
Definition at line 170 of file ParallelHelper.hpp.
Referenced by compute_next_independent_set(), and get_next_partition_boundary_vertex().
int MBMesquite::ParallelHelperImpl::nprocs [private] |
Definition at line 137 of file ParallelHelper.hpp.
Referenced by communicate_first_independent_set(), compute_first_independent_set(), compute_next_independent_set(), get_nprocs(), ParallelHelperImpl(), set_communicator(), smoothing_close(), and smoothing_init().
Definition at line 165 of file ParallelHelper.hpp.
Referenced by communicate_first_independent_set(), and communicate_next_independent_set().
Definition at line 164 of file ParallelHelper.hpp.
Referenced by communicate_next_independent_set(), compute_first_independent_set(), and get_next_partition_boundary_vertex().
int MBMesquite::ParallelHelperImpl::num_exportVtx [private] |
Definition at line 152 of file ParallelHelper.hpp.
Referenced by comm_smoothed_vtx_b(), comm_smoothed_vtx_b_no_all(), comm_smoothed_vtx_nb(), comm_smoothed_vtx_nb_no_all(), comm_smoothed_vtx_tnb(), comm_smoothed_vtx_tnb_no_all(), and compute_independent_set().
int MBMesquite::ParallelHelperImpl::num_vertex [private] |
Definition at line 142 of file ParallelHelper.hpp.
Referenced by smoothing_close(), and smoothing_init().
Definition at line 144 of file ParallelHelper.hpp.
Referenced by compute_first_independent_set(), compute_independent_set(), and smoothing_init().
Definition at line 145 of file ParallelHelper.hpp.
Referenced by communicate_next_independent_set(), compute_first_independent_set(), compute_independent_set(), get_next_partition_boundary_vertex(), and smoothing_init().
Definition at line 146 of file ParallelHelper.hpp.
Referenced by smoothing_init().
std::vector< size_t > MBMesquite::ParallelHelperImpl::part_gid [private] |
Definition at line 149 of file ParallelHelper.hpp.
Referenced by compute_independent_set(), ParallelHelperImpl(), and smoothing_init().
std::vector< int > MBMesquite::ParallelHelperImpl::part_proc_owner [private] |
Definition at line 148 of file ParallelHelper.hpp.
Referenced by compute_independent_set(), ParallelHelperImpl(), and smoothing_init().
std::vector< double > MBMesquite::ParallelHelperImpl::part_rand_number [private] |
Definition at line 151 of file ParallelHelper.hpp.
Referenced by compute_independent_set(), ParallelHelperImpl(), and smoothing_init().
std::vector< int > MBMesquite::ParallelHelperImpl::part_smoothed_flag [private] |
Definition at line 150 of file ParallelHelper.hpp.
Referenced by comm_smoothed_vtx_b(), comm_smoothed_vtx_b_no_all(), comm_smoothed_vtx_nb(), comm_smoothed_vtx_nb_no_all(), comm_smoothed_vtx_tnb(), comm_smoothed_vtx_tnb_no_all(), communicate_next_independent_set(), compute_first_independent_set(), compute_independent_set(), get_next_partition_boundary_vertex(), ParallelHelperImpl(), and smoothing_init().
std::vector< MBMesquite::Mesh::VertexHandle > MBMesquite::ParallelHelperImpl::part_vertices [private] |
Definition at line 147 of file ParallelHelper.hpp.
Referenced by comm_smoothed_vtx_b(), comm_smoothed_vtx_b_no_all(), comm_smoothed_vtx_nb(), comm_smoothed_vtx_nb_no_all(), comm_smoothed_vtx_tnb(), comm_smoothed_vtx_tnb_no_all(), compute_first_independent_set(), get_next_partition_boundary_vertex(), ParallelHelperImpl(), and smoothing_init().
int MBMesquite::ParallelHelperImpl::rank [private] |
Definition at line 136 of file ParallelHelper.hpp.
Referenced by comm_smoothed_vtx_b(), comm_smoothed_vtx_b_no_all(), comm_smoothed_vtx_nb(), comm_smoothed_vtx_nb_no_all(), comm_smoothed_vtx_tnb(), comm_smoothed_vtx_tnb_no_all(), communicate_histogram_to_zero(), communicate_min_max_to_zero(), communicate_next_independent_set(), communicate_power_sum_to_zero(), communicate_sums_to_zero(), compute_first_independent_set(), compute_independent_set(), compute_next_independent_set(), get_next_partition_boundary_vertex(), get_rank(), is_our_element(), is_our_vertex(), ParallelHelperImpl(), set_communicator(), smoothing_close(), and smoothing_init().
Definition at line 159 of file ParallelHelper.hpp.
Referenced by communicate_next_independent_set(), and smoothing_init().
Definition at line 158 of file ParallelHelper.hpp.
Referenced by communicate_next_independent_set(), and smoothing_init().
int MBMesquite::ParallelHelperImpl::unghost_num_procs [private] |
Definition at line 174 of file ParallelHelper.hpp.
Referenced by smoothing_close(), and smoothing_init().
int MBMesquite::ParallelHelperImpl::unghost_num_vtx [private] |
Definition at line 172 of file ParallelHelper.hpp.
Referenced by smoothing_close(), and smoothing_init().
std::vector< int > MBMesquite::ParallelHelperImpl::unghost_procs [private] |
Definition at line 175 of file ParallelHelper.hpp.
Referenced by smoothing_close(), and smoothing_init().
std::vector< int > MBMesquite::ParallelHelperImpl::unghost_procs_num_vtx [private] |
Definition at line 176 of file ParallelHelper.hpp.
Referenced by smoothing_close(), and smoothing_init().
std::vector< int > MBMesquite::ParallelHelperImpl::unghost_procs_offset [private] |
Definition at line 177 of file ParallelHelper.hpp.
Referenced by smoothing_close(), and smoothing_init().
std::vector< MBMesquite::Mesh::VertexHandle > MBMesquite::ParallelHelperImpl::unghost_vertices [private] |
Definition at line 173 of file ParallelHelper.hpp.
Referenced by compute_first_independent_set(), ParallelHelperImpl(), smoothing_close(), and smoothing_init().
std::vector< size_t > MBMesquite::ParallelHelperImpl::update_gid [private] |
Definition at line 179 of file ParallelHelper.hpp.
Referenced by smoothing_close(), and smoothing_init().
int MBMesquite::ParallelHelperImpl::update_num_procs [private] |
Definition at line 180 of file ParallelHelper.hpp.
Referenced by smoothing_close(), and smoothing_init().
int MBMesquite::ParallelHelperImpl::update_num_vtx [private] |
Definition at line 178 of file ParallelHelper.hpp.
Referenced by smoothing_close(), and smoothing_init().
std::vector< int > MBMesquite::ParallelHelperImpl::update_procs [private] |
Definition at line 181 of file ParallelHelper.hpp.
Referenced by smoothing_close(), and smoothing_init().
std::vector< int > MBMesquite::ParallelHelperImpl::update_procs_num_vtx [private] |
Definition at line 182 of file ParallelHelper.hpp.
Referenced by smoothing_close(), and smoothing_init().
std::vector< int > MBMesquite::ParallelHelperImpl::update_procs_offset [private] |
Definition at line 183 of file ParallelHelper.hpp.
Referenced by smoothing_close(), and smoothing_init().
std::vector< MBMesquite::Mesh::VertexHandle > MBMesquite::ParallelHelperImpl::vertices [private] |
Definition at line 141 of file ParallelHelper.hpp.
Referenced by ParallelHelperImpl(), smoothing_close(), and smoothing_init().
Definition at line 157 of file ParallelHelper.hpp.
Referenced by comm_smoothed_vtx_b(), comm_smoothed_vtx_b_no_all(), comm_smoothed_vtx_nb(), comm_smoothed_vtx_nb_no_all(), comm_smoothed_vtx_tnb(), comm_smoothed_vtx_tnb_no_all(), ParallelHelperImpl(), and smoothing_init().
std::vector< char > MBMesquite::ParallelHelperImpl::vtx_in_partition_boundary [private] |
Definition at line 143 of file ParallelHelper.hpp.
Referenced by ParallelHelperImpl(), and smoothing_init().
std::vector< std::vector< int > > MBMesquite::ParallelHelperImpl::vtx_off_proc_list [private] |
Definition at line 166 of file ParallelHelper.hpp.
Referenced by compute_independent_set(), ParallelHelperImpl(), and smoothing_init().
 1.7.6.1
1.7.6.1