|
MOAB: Mesh Oriented datABase
(version 5.4.1)
|
|
MOAB: Mesh Oriented datABase
(version 5.4.1)
|
#include <ParallelMergeMesh.hpp>
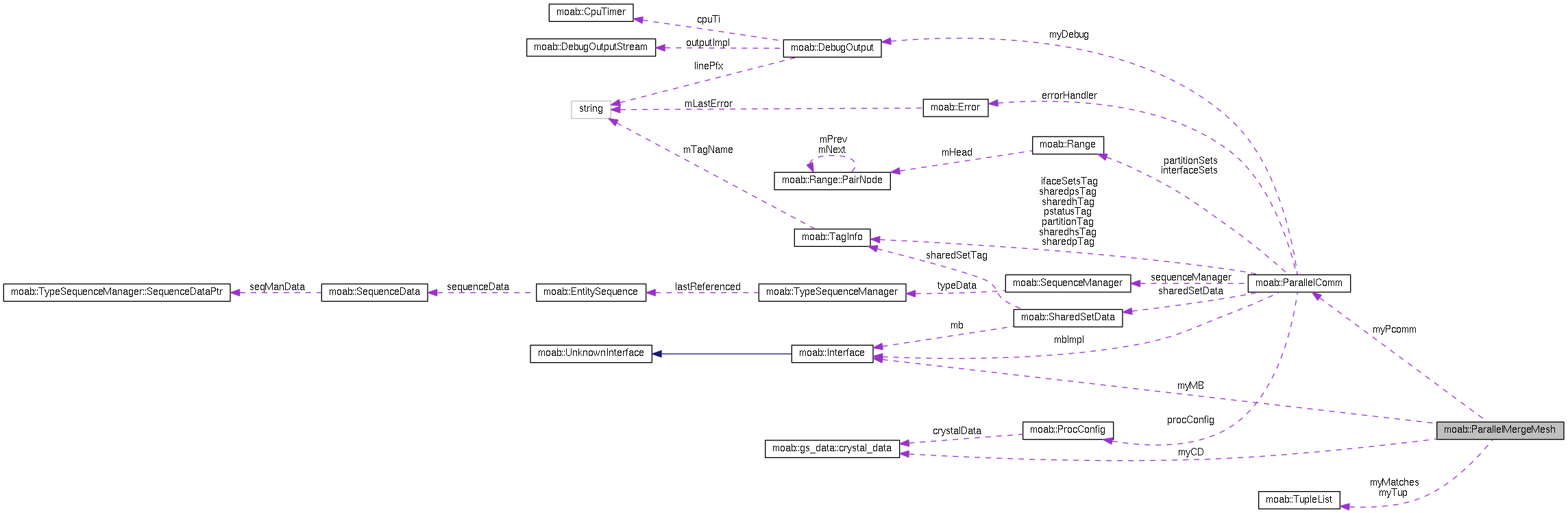
 Collaboration diagram for moab::ParallelMergeMesh:
Collaboration diagram for moab::ParallelMergeMesh:Public Member Functions | |
| ParallelMergeMesh (ParallelComm *pc, const double epsilon) | |
| ErrorCode | merge (EntityHandle levelset=0, bool skip_local_merge=false, int dim=-1) |
Private Member Functions | |
| ErrorCode | PerformMerge (EntityHandle levelset=0, bool skip_local_merge=false, int dim=-1) |
| ErrorCode | PopulateMySkinEnts (const EntityHandle meshset, int dim, bool skip_local_merge=false) |
| ErrorCode | GetGlobalBox (double *gbox) |
| ErrorCode | PopulateMyTup (double *gbox) |
| ErrorCode | PopulateMyMatches () |
| ErrorCode | SortMyMatches () |
| ErrorCode | TagSharedElements (int dim) |
| void | CleanUp () |
| ErrorCode | PartitionGlobalBox (double *gbox, double *lengths, int *parts) |
Static Private Member Functions | |
| static int | PartitionSide (double sideLeng, double restLen, unsigned numProcs, bool altRatio) |
| static void | SwapTuples (TupleList &tup, unsigned long a, unsigned long b) |
| static void | SortTuplesByReal (TupleList &tup, double eps2=0) |
| static void | PerformRealSort (TupleList &tup, unsigned long left, unsigned long right, double eps2, uint tup_mr) |
| static bool | TupleGreaterThan (TupleList &tup, unsigned long vrI, unsigned long vrJ, double eps2, uint tup_mr) |
Private Attributes | |
| ParallelComm * | myPcomm |
| Interface * | myMB |
| std::vector< Range > | mySkinEnts |
| double | myEps |
| TupleList | myTup |
| TupleList | myMatches |
| gs_data::crystal_data | myCD |
Definition at line 24 of file ParallelMergeMesh.hpp.
| moab::ParallelMergeMesh::ParallelMergeMesh | ( | ParallelComm * | pc, |
| const double | epsilon | ||
| ) |
Definition at line 20 of file ParallelMergeMesh.cpp.
References moab::ParallelComm::get_moab(), myMB, and mySkinEnts.
: myPcomm( pc ), myEps( epsilon ) { myMB = pc->get_moab(); mySkinEnts.resize( 4 ); }
| void moab::ParallelMergeMesh::CleanUp | ( | ) | [private] |
| ErrorCode moab::ParallelMergeMesh::GetGlobalBox | ( | double * | gbox | ) | [private] |
Definition at line 141 of file ParallelMergeMesh.cpp.
References moab::BoundBox::bMax, box(), moab::ParallelComm::comm(), ErrorCode, MB_CHK_ERR, MB_SUCCESS, myMB, myPcomm, mySkinEnts, size, and moab::BoundBox::update().
Referenced by PerformMerge().
{
ErrorCode rval;
/*Get Bounding Box*/
BoundBox box;
if( mySkinEnts[0].size() != 0 )
{
rval = box.update( *myMB, mySkinEnts[0] );MB_CHK_ERR( rval );
}
// Invert the max
box.bMax *= -1;
/*Communicate to all processors*/
MPI_Allreduce( (void*)&box, gbox, 6, MPI_DOUBLE, MPI_MIN, myPcomm->comm() );
/*Assemble Global Bounding Box*/
// Flip the max back
for( int i = 3; i < 6; i++ )
{
gbox[i] *= -1;
}
return MB_SUCCESS;
}
| ErrorCode moab::ParallelMergeMesh::merge | ( | EntityHandle | levelset = 0, |
| bool | skip_local_merge = false, |
||
| int | dim = -1 |
||
| ) |
Definition at line 28 of file ParallelMergeMesh.cpp.
References CleanUp(), ErrorCode, MB_CHK_ERR, and PerformMerge().
Referenced by moab::MeshGeneration::BrickInstance(), create_fine_mesh(), moab::NCHelperDomain::create_mesh(), moab::NCHelperScrip::create_mesh(), and main().
{
ErrorCode rval = PerformMerge( levelset, skip_local_merge, dim );MB_CHK_ERR( rval );
CleanUp();
return rval;
}
| ErrorCode moab::ParallelMergeMesh::PartitionGlobalBox | ( | double * | gbox, |
| double * | lengths, | ||
| int * | parts | ||
| ) | [private] |
Definition at line 287 of file ParallelMergeMesh.cpp.
References MB_SUCCESS, myEps, myPcomm, PartitionSide(), and moab::ParallelComm::size().
Referenced by PopulateMyTup().
{
// Determine the length of each side
double xLen = gbox[3] - gbox[0];
double yLen = gbox[4] - gbox[1];
double zLen = gbox[5] - gbox[2];
// avoid division by zero for deciding the way to partition the global box
// make all sides of the box at least myEps
// it can be zero in some cases, so not possible to compare the ratios :) for best division
if (xLen < myEps) xLen = myEps;
if (yLen < myEps) yLen = myEps;
if (zLen < myEps) zLen = myEps;
unsigned numProcs = myPcomm->size();
// Partition sides from the longest to shortest lengths
// If x is the longest side
if( xLen >= yLen && xLen >= zLen )
{
parts[0] = PartitionSide( xLen, yLen * zLen, numProcs, true );
numProcs /= parts[0];
// If y is second longest
if( yLen >= zLen )
{
parts[1] = PartitionSide( yLen, zLen, numProcs, false );
parts[2] = numProcs / parts[1];
}
// If z is the longer
else
{
parts[2] = PartitionSide( zLen, yLen, numProcs, false );
parts[1] = numProcs / parts[2];
}
}
// If y is the longest side
else if( yLen >= zLen )
{
parts[1] = PartitionSide( yLen, xLen * zLen, numProcs, true );
numProcs /= parts[1];
// If x is the second longest
if( xLen >= zLen )
{
parts[0] = PartitionSide( xLen, zLen, numProcs, false );
parts[2] = numProcs / parts[0];
}
// If z is the second longest
else
{
parts[2] = PartitionSide( zLen, xLen, numProcs, false );
parts[0] = numProcs / parts[2];
}
}
// If z is the longest side
else
{
parts[2] = PartitionSide( zLen, xLen * yLen, numProcs, true );
numProcs /= parts[2];
// If x is the second longest
if( xLen >= yLen )
{
parts[0] = PartitionSide( xLen, yLen, numProcs, false );
parts[1] = numProcs / parts[0];
}
// If y is the second longest
else
{
parts[1] = PartitionSide( yLen, xLen, numProcs, false );
parts[0] = numProcs / parts[1];
}
}
// Divide up each side to give the lengths
lengths[0] = xLen / (double)parts[0];
lengths[1] = yLen / (double)parts[1];
lengths[2] = zLen / (double)parts[2];
return MB_SUCCESS;
}
| int moab::ParallelMergeMesh::PartitionSide | ( | double | sideLeng, |
| double | restLen, | ||
| unsigned | numProcs, | ||
| bool | altRatio | ||
| ) | [static, private] |
Definition at line 365 of file ParallelMergeMesh.cpp.
Referenced by PartitionGlobalBox().
{
// If theres only 1 processor, then just return 1
if( numProcs == 1 )
{
return 1;
}
// Initialize with the ratio of 1 proc
double ratio = -DBL_MAX;
unsigned factor = 1;
// We need to be able to save the last ratio and factor (for comparison)
double oldRatio = ratio;
double oldFactor = 1;
// This is the ratio were shooting for
double goalRatio = sideLen / restLen;
// Calculate the divisor and numerator power
// This avoid if statements in the loop and is useful since both calculations are similar
double divisor, p;
if( altRatio )
{
divisor = (double)numProcs * sideLen;
p = 3;
}
else
{
divisor = (double)numProcs;
p = 2;
}
// Find each possible factor
for( unsigned i = 2; i <= numProcs / 2; i++ )
{
// If it is a factor...
if( numProcs % i == 0 )
{
// We need to save the past factor
oldRatio = ratio;
oldFactor = factor;
// There are 2 different ways to calculate the ratio:
// Comparing 1 side to 2 sides: (i*i*i)/(numProcs*x)
// Justification: We have a ratio x:y:z (side Lengths) == a:b:c (procs). So a=kx,
// b=ky, c=kz. Also, abc=n (numProcs) => bc = n/a. Also, a=kx => k=a/x => 1/k=x/a And so
// x/(yz) == (kx)/(kyz) == (kx)/(kykz(1/k)) == a/(bc(x/a)) == a/((n/a)(x/a)) == a^3/(nx).
// Comparing 1 side to 1 side: (i*i)/numprocs
// Justification: i/(n/i) == i^2/n
ratio = pow( (double)i, p ) / divisor;
factor = i;
// Once we have passed the goal ratio, we can break since we'll only move away from the
// goal ratio
if( ratio >= goalRatio )
{
break;
}
}
}
// If we haven't reached the goal ratio yet, check out factor = numProcs
if( ratio < goalRatio )
{
oldRatio = ratio;
oldFactor = factor;
factor = numProcs;
ratio = pow( (double)numProcs, p ) / divisor;
}
// Figure out if our oldRatio is better than ratio
if( fabs( ratio - goalRatio ) > fabs( oldRatio - goalRatio ) )
{
factor = oldFactor;
}
// Return our findings
return factor;
}
| ErrorCode moab::ParallelMergeMesh::PerformMerge | ( | EntityHandle | levelset = 0, |
| bool | skip_local_merge = false, |
||
| int | dim = -1 |
||
| ) | [private] |
Definition at line 36 of file ParallelMergeMesh.cpp.
References moab::ParallelComm::comm(), ErrorCode, moab::Interface::get_dimension(), GetGlobalBox(), moab::TupleList::initialize(), MB_CHK_ERR, MB_SUCCESS, myCD, myEps, myMatches, myMB, myPcomm, mySkinEnts, myTup, PopulateMyMatches(), PopulateMySkinEnts(), PopulateMyTup(), moab::TupleList::reset(), size, moab::ParallelComm::size(), SortMyMatches(), SortTuplesByReal(), and TagSharedElements().
Referenced by merge().
{
// Get the mesh dimension
ErrorCode rval;
if( dim < 0 )
{
rval = myMB->get_dimension( dim );MB_CHK_ERR( rval );
}
// Get the local skin elements
rval = PopulateMySkinEnts( levelset, dim, skip_local_merge );
// If there is only 1 proc, we can return now
if( rval != MB_SUCCESS || myPcomm->size() == 1 )
{
return rval;
}
// Determine the global bounding box
double gbox[6];
rval = GetGlobalBox( gbox );MB_CHK_ERR( rval );
/* Assemble The Destination Tuples */
// Get a list of tuples which contain (toProc, handle, x,y,z)
myTup.initialize( 1, 0, 1, 3, mySkinEnts[0].size() );
rval = PopulateMyTup( gbox );MB_CHK_ERR( rval );
/* Gather-Scatter Tuple
-tup comes out as (remoteProc,handle,x,y,z) */
myCD.initialize( myPcomm->comm() );
// 1 represents dynamic tuple, 0 represents index of the processor to send to
myCD.gs_transfer( 1, myTup, 0 );
/* Sort By X,Y,Z
-Utilizes a custom quick sort incorporating epsilon*/
SortTuplesByReal( myTup, myEps );
// Initialize another tuple list for matches
myMatches.initialize( 2, 0, 2, 0, mySkinEnts[0].size() );
// ID the matching tuples
rval = PopulateMyMatches();MB_CHK_ERR( rval );
// We can free up the tuple myTup now
myTup.reset();
/*Gather-Scatter Again*/
// 1 represents dynamic list, 0 represents proc index to send tuple to
myCD.gs_transfer( 1, myMatches, 0 );
// We can free up the crystal router now
myCD.reset();
// Sort the matches tuple list
SortMyMatches();
// Tag the shared elements
rval = TagSharedElements( dim );MB_CHK_ERR( rval );
// Free up the matches tuples
myMatches.reset();
return rval;
}
| void moab::ParallelMergeMesh::PerformRealSort | ( | TupleList & | tup, |
| unsigned long | left, | ||
| unsigned long | right, | ||
| double | eps2, | ||
| uint | tup_mr | ||
| ) | [static, private] |
Definition at line 691 of file ParallelMergeMesh.cpp.
References swap(), SwapTuples(), t, and TupleGreaterThan().
Referenced by SortTuplesByReal().
{
// If list size is only 1 or 0 return
if( left + 1 >= right )
{
return;
}
unsigned long swap = left, tup_l = left * tup_mr, tup_t = tup_l + tup_mr;
// Swap the median with the left position for a (hopefully) better split
SwapTuples( tup, left, ( left + right ) / 2 );
// Partition the data
for( unsigned long t = left + 1; t < right; t++ )
{
// If the left value(pivot) is greater than t_val, swap it into swap
if( TupleGreaterThan( tup, tup_l, tup_t, eps, tup_mr ) )
{
swap++;
SwapTuples( tup, swap, t );
}
tup_t += tup_mr;
}
// Swap so that position swap is in the correct position
SwapTuples( tup, left, swap );
// Sort left and right of swap
PerformRealSort( tup, left, swap, eps, tup_mr );
PerformRealSort( tup, swap + 1, right, eps, tup_mr );
}
| ErrorCode moab::ParallelMergeMesh::PopulateMyMatches | ( | ) | [private] |
Definition at line 441 of file ParallelMergeMesh.cpp.
References moab::TupleList::disableWriteAccess(), moab::TupleList::enableWriteAccess(), moab::TupleList::get_max(), moab::TupleList::get_n(), moab::TupleList::get_writeEnabled(), moab::TupleList::getTupleSize(), moab::TupleList::inc_n(), moab::CartVect::length_squared(), MB_SUCCESS, myEps, myMatches, myTup, moab::TupleList::resize(), moab::TupleList::vi_rd, moab::TupleList::vi_wr, moab::TupleList::vr_rd, moab::TupleList::vul_rd, and moab::TupleList::vul_wr.
Referenced by PerformMerge().
{
// Counters for accessing tuples more efficiently
unsigned long i = 0, mat_i = 0, mat_ul = 0, j = 0, tup_r = 0;
double eps2 = myEps * myEps;
uint tup_mi, tup_ml, tup_mul, tup_mr;
myTup.getTupleSize( tup_mi, tup_ml, tup_mul, tup_mr );
bool canWrite = myMatches.get_writeEnabled();
if( !canWrite ) myMatches.enableWriteAccess();
while( ( i + 1 ) < myTup.get_n() )
{
// Proximity Comparison
double xi = myTup.vr_rd[tup_r], yi = myTup.vr_rd[tup_r + 1], zi = myTup.vr_rd[tup_r + 2];
bool done = false;
while( !done )
{
j++;
tup_r += tup_mr;
if( j >= myTup.get_n() )
{
break;
}
CartVect cv( myTup.vr_rd[tup_r] - xi, myTup.vr_rd[tup_r + 1] - yi, myTup.vr_rd[tup_r + 2] - zi );
if( cv.length_squared() > eps2 )
{
done = true;
}
}
// Allocate the tuple list before adding matches
while( myMatches.get_n() + ( j - i ) * ( j - i - 1 ) >= myMatches.get_max() )
{
myMatches.resize( myMatches.get_max() ? myMatches.get_max() + myMatches.get_max() / 2 + 1 : 2 );
}
// We now know that tuples [i to j) exclusive match.
// If n tuples match, n*(n-1) match tuples will be made
// tuples are of the form (proc1,proc2,handle1,handle2)
if( i + 1 < j )
{
int kproc = i * tup_mi;
unsigned long khand = i * tup_mul;
for( unsigned long k = i; k < j; k++ )
{
int lproc = kproc + tup_mi;
unsigned long lhand = khand + tup_mul;
for( unsigned long l = k + 1; l < j; l++ )
{
myMatches.vi_wr[mat_i++] = myTup.vi_rd[kproc]; // proc1
myMatches.vi_wr[mat_i++] = myTup.vi_rd[lproc]; // proc2
myMatches.vul_wr[mat_ul++] = myTup.vul_rd[khand]; // handle1
myMatches.vul_wr[mat_ul++] = myTup.vul_rd[lhand]; // handle2
myMatches.inc_n();
myMatches.vi_wr[mat_i++] = myTup.vi_rd[lproc]; // proc1
myMatches.vi_wr[mat_i++] = myTup.vi_rd[kproc]; // proc2
myMatches.vul_wr[mat_ul++] = myTup.vul_rd[lhand]; // handle1
myMatches.vul_wr[mat_ul++] = myTup.vul_rd[khand]; // handle2
myMatches.inc_n();
lproc += tup_mi;
lhand += tup_mul;
}
kproc += tup_mi;
khand += tup_mul;
} // End for(int k...
}
i = j;
} // End while(i+1<tup.n)
if( !canWrite ) myMatches.disableWriteAccess();
return MB_SUCCESS;
}
| ErrorCode moab::ParallelMergeMesh::PopulateMySkinEnts | ( | const EntityHandle | meshset, |
| int | dim, | ||
| bool | skip_local_merge = false |
||
| ) | [private] |
Definition at line 100 of file ParallelMergeMesh.cpp.
References moab::Range::clear(), moab::Range::empty(), ErrorCode, moab::Skinner::find_skin(), moab::Interface::get_entities_by_dimension(), MB_CHK_ERR, MB_SUCCESS, moab::MergeMesh::merge_entities(), myEps, myMB, myPcomm, mySkinEnts, and moab::ParallelComm::size().
Referenced by PerformMerge().
{
/*Merge Mesh Locally*/
// Get all dim dimensional entities
Range ents;
ErrorCode rval = myMB->get_entities_by_dimension( meshset, dim, ents );MB_CHK_ERR( rval );
if( ents.empty() && dim == 3 )
{
dim--;
rval = myMB->get_entities_by_dimension( meshset, dim, ents );MB_CHK_ERR( rval ); // maybe dimension 2
}
// Merge Mesh Locally
if( !skip_local_merge )
{
MergeMesh merger( myMB, false );
merger.merge_entities( ents, myEps );
// We can return if there is only 1 proc
if( rval != MB_SUCCESS || myPcomm->size() == 1 )
{
return rval;
}
// Rebuild the ents range
ents.clear();
rval = myMB->get_entities_by_dimension( meshset, dim, ents );MB_CHK_ERR( rval );
}
/*Get Skin
-Get Range of all dimensional entities
-skinEnts[i] is the skin entities of dimension i*/
Skinner skinner( myMB );
for( int skin_dim = dim; skin_dim >= 0; skin_dim-- )
{
rval = skinner.find_skin( meshset, ents, skin_dim, mySkinEnts[skin_dim] );MB_CHK_ERR( rval );
}
return MB_SUCCESS;
}
| ErrorCode moab::ParallelMergeMesh::PopulateMyTup | ( | double * | gbox | ) | [private] |
Definition at line 168 of file ParallelMergeMesh.cpp.
References moab::TupleList::disableWriteAccess(), moab::TupleList::enableWriteAccess(), ErrorCode, moab::Interface::get_coords(), moab::TupleList::get_max(), moab::TupleList::get_n(), moab::TupleList::get_writeEnabled(), moab::TupleList::inc_n(), MB_CHK_ERR, MB_SUCCESS, myEps, myMB, mySkinEnts, myTup, PartitionGlobalBox(), moab::TupleList::resize(), moab::TupleList::vi_wr, moab::TupleList::vr_wr, and moab::TupleList::vul_wr.
Referenced by PerformMerge().
{
/*Figure out how do partition the global box*/
double lengths[3];
int parts[3];
ErrorCode rval = PartitionGlobalBox( gbox, lengths, parts );MB_CHK_ERR( rval );
/* Get Skin Coordinates, Vertices */
double* x = new double[mySkinEnts[0].size()];
double* y = new double[mySkinEnts[0].size()];
double* z = new double[mySkinEnts[0].size()];
rval = myMB->get_coords( mySkinEnts[0], x, y, z );
if( rval != MB_SUCCESS )
{
// Prevent Memory Leak
delete[] x;
delete[] y;
delete[] z;
return rval;
}
// Initialize variable to be used in the loops
std::vector< int > toProcs;
int xPart, yPart, zPart, xEps, yEps, zEps, baseProc;
unsigned long long tup_i = 0, tup_ul = 0, tup_r = 0, count = 0;
// These are boolean to determine if the vertex is on close enough to a given border
bool xDup, yDup, zDup;
bool canWrite = myTup.get_writeEnabled();
if( !canWrite ) myTup.enableWriteAccess();
// Go through each vertex
for( Range::iterator it = mySkinEnts[0].begin(); it != mySkinEnts[0].end(); ++it )
{
xDup = false;
yDup = false;
zDup = false;
// Figure out which x,y,z partition the element is in.
xPart = static_cast< int >( floor( ( x[count] - gbox[0] ) / lengths[0] ) );
xPart = ( xPart < parts[0] ? xPart : parts[0] - 1 ); // Make sure it stays within the bounds
yPart = static_cast< int >( floor( ( y[count] - gbox[1] ) / lengths[1] ) );
yPart = ( yPart < parts[1] ? yPart : parts[1] - 1 ); // Make sure it stays within the bounds
zPart = static_cast< int >( floor( ( z[count] - gbox[2] ) / lengths[2] ) );
zPart = ( zPart < parts[2] ? zPart : parts[2] - 1 ); // Make sure it stays within the bounds
// Figure out the partition with the addition of Epsilon
xEps = static_cast< int >( floor( ( x[count] - gbox[0] + myEps ) / lengths[0] ) );
yEps = static_cast< int >( floor( ( y[count] - gbox[1] + myEps ) / lengths[1] ) );
zEps = static_cast< int >( floor( ( z[count] - gbox[2] + myEps ) / lengths[2] ) );
// Figure out if the vertex needs to be sent to multiple procs
xDup = ( xPart != xEps && xEps < parts[0] );
yDup = ( yPart != yEps && yEps < parts[1] );
zDup = ( zPart != zEps && zEps < parts[2] );
// Add appropriate processors to the vector
baseProc = xPart + yPart * parts[0] + zPart * parts[0] * parts[1];
toProcs.push_back( baseProc );
if( xDup )
{
toProcs.push_back( baseProc + 1 ); // Get partition to the right
}
if( yDup )
{
// Partition up 1
toProcs.push_back( baseProc + parts[0] );
}
if( zDup )
{
// Partition above 1
toProcs.push_back( baseProc + parts[0] * parts[1] );
}
if( xDup && yDup )
{
// Partition up 1 and right 1
toProcs.push_back( baseProc + parts[0] + 1 );
}
if( xDup && zDup )
{
// Partition right 1 and above 1
toProcs.push_back( baseProc + parts[0] * parts[1] + 1 );
}
if( yDup && zDup )
{
// Partition up 1 and above 1
toProcs.push_back( baseProc + parts[0] * parts[1] + parts[0] );
}
if( xDup && yDup && zDup )
{
// Partition right 1, up 1, and above 1
toProcs.push_back( baseProc + parts[0] * parts[1] + parts[0] + 1 );
}
// Grow the tuple list if necessary
while( myTup.get_n() + toProcs.size() >= myTup.get_max() )
{
myTup.resize( myTup.get_max() ? myTup.get_max() + myTup.get_max() / 2 + 1 : 2 );
}
// Add each proc as a tuple
for( std::vector< int >::iterator proc = toProcs.begin(); proc != toProcs.end(); ++proc )
{
myTup.vi_wr[tup_i++] = *proc;
myTup.vul_wr[tup_ul++] = *it;
myTup.vr_wr[tup_r++] = x[count];
myTup.vr_wr[tup_r++] = y[count];
myTup.vr_wr[tup_r++] = z[count];
myTup.inc_n();
}
count++;
toProcs.clear();
}
delete[] x;
delete[] y;
delete[] z;
if( !canWrite ) myTup.disableWriteAccess();
return MB_SUCCESS;
}
| ErrorCode moab::ParallelMergeMesh::SortMyMatches | ( | ) | [private] |
Definition at line 518 of file ParallelMergeMesh.cpp.
References MB_SUCCESS, myMatches, mySkinEnts, moab::TupleList::buffer::reset(), size, and moab::TupleList::sort().
Referenced by PerformMerge().
{
TupleList::buffer buf( mySkinEnts[0].size() );
// Sorts are necessary to check for doubles
// Sort by remote handle
myMatches.sort( 3, &buf );
// Sort by matching proc
myMatches.sort( 1, &buf );
// Sort by local handle
myMatches.sort( 2, &buf );
buf.reset();
return MB_SUCCESS;
}
| void moab::ParallelMergeMesh::SortTuplesByReal | ( | TupleList & | tup, |
| double | eps2 = 0 |
||
| ) | [static, private] |
Definition at line 624 of file ParallelMergeMesh.cpp.
References moab::TupleList::disableWriteAccess(), moab::TupleList::enableWriteAccess(), eps, moab::TupleList::get_n(), moab::TupleList::get_writeEnabled(), moab::TupleList::getTupleSize(), and PerformRealSort().
Referenced by PerformMerge().
{
bool canWrite = tup.get_writeEnabled();
if( !canWrite ) tup.enableWriteAccess();
uint mi, ml, mul, mr;
tup.getTupleSize( mi, ml, mul, mr );
PerformRealSort( tup, 0, tup.get_n(), eps, mr );
if( !canWrite ) tup.disableWriteAccess();
}
| void moab::ParallelMergeMesh::SwapTuples | ( | TupleList & | tup, |
| unsigned long | a, | ||
| unsigned long | b | ||
| ) | [static, private] |
Definition at line 637 of file ParallelMergeMesh.cpp.
References moab::TupleList::getTupleSize(), t, moab::TupleList::vi_rd, moab::TupleList::vi_wr, moab::TupleList::vl_rd, moab::TupleList::vl_wr, moab::TupleList::vr_rd, moab::TupleList::vr_wr, moab::TupleList::vul_rd, and moab::TupleList::vul_wr.
Referenced by PerformRealSort().
{
if( a == b ) return;
uint mi, ml, mul, mr;
tup.getTupleSize( mi, ml, mul, mr );
// Swap mi
unsigned long a_val = a * mi, b_val = b * mi;
for( unsigned long i = 0; i < mi; i++ )
{
sint t = tup.vi_rd[a_val];
tup.vi_wr[a_val] = tup.vi_rd[b_val];
tup.vi_wr[b_val] = t;
a_val++;
b_val++;
}
// Swap ml
a_val = a * ml;
b_val = b * ml;
for( unsigned long i = 0; i < ml; i++ )
{
slong t = tup.vl_rd[a_val];
tup.vl_wr[a_val] = tup.vl_rd[b_val];
tup.vl_wr[b_val] = t;
a_val++;
b_val++;
}
// Swap mul
a_val = a * mul;
b_val = b * mul;
for( unsigned long i = 0; i < mul; i++ )
{
Ulong t = tup.vul_rd[a_val];
tup.vul_wr[a_val] = tup.vul_rd[b_val];
tup.vul_wr[b_val] = t;
a_val++;
b_val++;
}
// Swap mr
a_val = a * mr;
b_val = b * mr;
for( unsigned long i = 0; i < mr; i++ )
{
realType t = tup.vr_rd[a_val];
tup.vr_wr[a_val] = tup.vr_rd[b_val];
tup.vr_wr[b_val] = t;
a_val++;
b_val++;
}
}
| ErrorCode moab::ParallelMergeMesh::TagSharedElements | ( | int | dim | ) | [private] |
Definition at line 533 of file ParallelMergeMesh.cpp.
References moab::Range::begin(), moab::ParallelComm::create_iface_pc_links(), moab::ParallelComm::create_interface_sets(), moab::Interface::dimension_from_handle(), moab::Range::end(), moab::Range::erase(), ErrorCode, moab::ParallelComm::exchange_ghost_cells(), moab::GeomUtil::first(), moab::Interface::get_adjacencies(), moab::Interface::get_entities_by_handle(), moab::ParallelComm::get_interface_procs(), moab::ParallelComm::get_proc_nvecs(), moab::Range::lower_bound(), MAX_SHARING_PROCS, MB_SUCCESS, moab::Range::merge(), myMatches, myMB, myPcomm, mySkinEnts, moab::ParallelComm::partitionSets, moab::Range::rbegin(), moab::ParallelComm::tag_shared_verts(), moab::CN::TypeDimensionMap, moab::Interface::UNION, and moab::Range::upper_bound().
Referenced by PerformMerge().
{
// Manipulate the matches list to tag vertices and entities
// Set up proc ents
Range proc_ents;
ErrorCode rval;
// get the entities in the partition sets
for( Range::iterator rit = myPcomm->partitionSets.begin(); rit != myPcomm->partitionSets.end(); ++rit )
{
Range tmp_ents;
rval = myMB->get_entities_by_handle( *rit, tmp_ents, true );
if( MB_SUCCESS != rval )
{
return rval;
}
proc_ents.merge( tmp_ents );
}
if( myMB->dimension_from_handle( *proc_ents.rbegin() ) != myMB->dimension_from_handle( *proc_ents.begin() ) )
{
Range::iterator lower = proc_ents.lower_bound( CN::TypeDimensionMap[0].first ),
upper = proc_ents.upper_bound( CN::TypeDimensionMap[dim - 1].second );
proc_ents.erase( lower, upper );
}
// This vector doesn't appear to be used but its in resolve_shared_ents
int maxp = -1;
std::vector< int > sharing_procs( MAX_SHARING_PROCS );
std::fill( sharing_procs.begin(), sharing_procs.end(), maxp );
// get ents shared by 1 or n procs
std::map< std::vector< int >, std::vector< EntityHandle > > proc_nranges;
Range proc_verts;
rval = myMB->get_adjacencies( proc_ents, 0, false, proc_verts, Interface::UNION );
if( rval != MB_SUCCESS )
{
return rval;
}
rval = myPcomm->tag_shared_verts( myMatches, proc_nranges, proc_verts );
if( rval != MB_SUCCESS )
{
return rval;
}
// get entities shared by 1 or n procs
rval = myPcomm->get_proc_nvecs( dim, dim - 1, &mySkinEnts[0], proc_nranges );
if( rval != MB_SUCCESS )
{
return rval;
}
// create the sets for each interface; store them as tags on
// the interface instance
Range iface_sets;
rval = myPcomm->create_interface_sets( proc_nranges );
if( rval != MB_SUCCESS )
{
return rval;
}
// establish comm procs and buffers for them
std::set< unsigned int > procs;
rval = myPcomm->get_interface_procs( procs, true );
if( rval != MB_SUCCESS )
{
return rval;
}
// resolve shared entity remote handles; implemented in ghost cell exchange
// code because it's so similar
rval = myPcomm->exchange_ghost_cells( -1, -1, 0, true, true );
if( rval != MB_SUCCESS )
{
return rval;
}
// now build parent/child links for interface sets
rval = myPcomm->create_iface_pc_links();
return rval;
}
| bool moab::ParallelMergeMesh::TupleGreaterThan | ( | TupleList & | tup, |
| unsigned long | vrI, | ||
| unsigned long | vrJ, | ||
| double | eps2, | ||
| uint | tup_mr | ||
| ) | [static, private] |
Definition at line 728 of file ParallelMergeMesh.cpp.
References check(), and moab::TupleList::vr_rd.
Referenced by PerformRealSort().
{
unsigned check = 0;
while( check < tup_mr )
{
// If the values are the same
if( fabs( tup.vr_rd[vrI + check] - tup.vr_rd[vrJ + check] ) <= eps )
{
check++;
continue;
}
// If I greater than J
else if( tup.vr_rd[vrI + check] > tup.vr_rd[vrJ + check] )
{
return true;
}
// If J greater than I
else
{
return false;
}
}
// All Values are the same
return false;
}
Definition at line 38 of file ParallelMergeMesh.hpp.
Referenced by CleanUp(), and PerformMerge().
double moab::ParallelMergeMesh::myEps [private] |
Definition at line 36 of file ParallelMergeMesh.hpp.
Referenced by PartitionGlobalBox(), PerformMerge(), PopulateMyMatches(), PopulateMySkinEnts(), and PopulateMyTup().
TupleList moab::ParallelMergeMesh::myMatches [private] |
Definition at line 37 of file ParallelMergeMesh.hpp.
Referenced by CleanUp(), PerformMerge(), PopulateMyMatches(), SortMyMatches(), and TagSharedElements().
Interface* moab::ParallelMergeMesh::myMB [private] |
Definition at line 34 of file ParallelMergeMesh.hpp.
Referenced by GetGlobalBox(), ParallelMergeMesh(), PerformMerge(), PopulateMySkinEnts(), PopulateMyTup(), and TagSharedElements().
ParallelComm* moab::ParallelMergeMesh::myPcomm [private] |
Definition at line 33 of file ParallelMergeMesh.hpp.
Referenced by GetGlobalBox(), PartitionGlobalBox(), PerformMerge(), PopulateMySkinEnts(), and TagSharedElements().
std::vector< Range > moab::ParallelMergeMesh::mySkinEnts [private] |
Definition at line 35 of file ParallelMergeMesh.hpp.
Referenced by GetGlobalBox(), ParallelMergeMesh(), PerformMerge(), PopulateMySkinEnts(), PopulateMyTup(), SortMyMatches(), and TagSharedElements().
TupleList moab::ParallelMergeMesh::myTup [private] |
Definition at line 37 of file ParallelMergeMesh.hpp.
Referenced by CleanUp(), PerformMerge(), PopulateMyMatches(), and PopulateMyTup().
 1.7.6.1
1.7.6.1